Lab 7: LISA regression
GEOG-364 - Spatial Analysis
Welcome to Lab 7!
The aim of this lab is to continue work on autocorrelation and to start regression. By the end of the lab you will be able to:
- Load data from shapefiles??
- Explore local spatial autocorrelation and spatial regression.
In this lab, I want to assess the relationship between the number of people who earn over $75000 dollars and population density in Chicago. Your job is to create a different regression analysis for your own data.
We will practice two new techniques, LISA (local auto-regression) to see if each variable is auto-correlated with itself, then actual regression - to understand the relationship between the two.
Now you are getting more experienced in R, I will provide a worked example then get you to do something similar on your own data. As much as possible I will refer to the tutorials, but remember they are there and remember that you also have your previous labs. I am purposefully not showing the code for the parts that you have done before, so this lab will be much harder if you have not finished Lab 6.
This is a longer lab. You have 2 weeks. I will consider awarding exceptional labs course credit at my discretion
See your canvas assignment here.
Need help? Add a screenshot/question to the discussion board here: LAB 7 DISCUSSION BOARD
A: Set up the lab NEW
A1: Sign up for Census API (if you didn’t last week)
IF YOU DIDN’T LAST WEEK: You can easily access US census data within R, but you need to sign up in advance for a password.
https://api.census.gov/data/key_signup.html
You can use Penn State as the organisation. This is just you promising that you will follow the terms and conditions when using this data. In a few minutes, e-mail you a personal access code. Click the link in the e-mail to activate.
A2: Create your lab project
Follow the instructions in Labs 1-4 to create your project file and a blank markdown document. e.g.
Open R-Studio. Create a new R-Project in your GEOG-364 folder called
GEOG364_Lab7_PROJECT.Make a copy of the lab template Rmd file and move it into your project folder.
DOUBLE CLICK ON THE GEOG364_Lab7_PROJECT.RPROJ FILE IN YOUR PROJECT FOLDER TO OPEN R.
IF YOU AR ON R-STUDIO CLOUD Re-install the packages AND THEN the two remotes commands by coping BOTH CODE CHUNKS into the console Tutorial 2 bulk download: by
Click on your lab 7 .Rmd file in the files tab to open the script
(You should not have to search if you are in your Lab 7 project):- Change the title to Lab 7.
- Change the theme if you like or add in any other features
- Remember you can edit your lab in the “editor” mode by clicking on the A at the top right
- Change the title to Lab 7.
STEP 5 UPDATE 2 - PACMAN IS RUBBISH
It turns out that pacman doesn’t work for some people when you press knit. MASSIVE THANKS to Zach, Riley and Fin for figuring this out. OK! Let’s go back to our old system. If pacman works for you - nice! This is here in case you need it.
Set your TOP CODE CHUNK TO BE THE SAME AS LAB 4/5/6 WITH THESE LIBRARIES. You will need to install any libraries you are missing. See Tutorial 2b Packages: if you can’t remember how.
knitr::opts_chunk$set(echo = TRUE,
message=FALSE,warning=FALSE)
# YOU MIGHT NEED TO INSTALL SOME OF THESE - RUN A FEW TIMES AND SEE WHAT HAPPENS
library(corrplot)
library(hrbrthemes)
library(olsrr)
library(plotly)
library(raster)
library(readxl)
library(rnaturalearth)
library(rmapshaper)
library(sf)
library(sp)
library(skimr)
library(spatialreg)
library(spatialEco)
library(spdep)
library(tidyverse)
library(tidycensus)
library(tigris)
library(tmap)
library(units)
library(USAboundaries)
library(viridis)
library(VIM)
Run the code chunk a few times and check there are no errors.
B: Spatial Data Wrangling (repeating lab 6)
First I am showing you a worked example. Save a copy of your R script as something like Lab 7 tutorial and getting the tutorial running on the example data for Chicago, adding in any code that I didn’t put in. As much as possible I will refer to the tutorials, but remember they are there and remember that you also have your previous labs. I am purposefully not showing the code for the parts that you have done before, but I have written down exactly how I worked each part out.
THEN in the challenge, you will do something similar on your own data - so you can make a copy of your tutorial file - and then start slowly changing things to match your own city.
**DO NOT INCLUDE THE TUTORIAL EXAMPLE IN YOUR FINAL REPORT! Make a separate markdown file if you want to keep it. You will be marked down if it is there.
Download the data from ACS
First, I used Tutorial 6Ec get_ACS: edit the get_acs command to download American Community Survey data for Illinois at a census tract spatial scale. A census tract is similar to a zip code, a much finer spatial scale than a county.
THE ONLY WAY YOU WILL KNOW HOW TO DO THIS IS TO LOOK AT TUTORIAL 6Ec.
I chose to download these variables. There are more variables than I need, but including so you can see some more census codes.
- housevalue (“B25075_001”) : house value
- totp (“B05012_001”) : total population
- tothouse (“B25001_001”) : total housing units
- med.income (“B19013_001”) : median income
- income.gt75 (“B06010_011”) : number of people making > 75000 USD
- for.born (“B05012_003”) : number of foreign born people
- house.age (“B25035_001”) : average house age
- month.house.cost (“B25105_001”) : monthly house expenditures
- med.gross.rent (“B25064_001”) : median rent
- workhome (“B08101_049”) : number who work from home
- owneroccupied (“B25003_002”) : total owner occupied
- totalbeds (“B25041_001”) : total number of beds in the house
- broadband (“B28002_004”) : total with access to broadband
You can see the data summarized here. Each column ending in E means the estimate of the value in each census tract and the column ending in M means the margin of error.
head(IL.Census.sf)## Simple feature collection with 6 features and 28 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -91.3937 ymin: 39.93667 xmax: -88.2049 ymax: 41.40851
## Geodetic CRS: NAD83
## GEOID NAME housevalueE
## 1 17001000202 Census Tract 2.02, Adams County, Illinois 721
## 2 17011965100 Census Tract 9651, Bureau County, Illinois 1292
## 3 17019000301 Census Tract 3.01, Champaign County, Illinois 11
## 4 17019000700 Census Tract 7, Champaign County, Illinois 691
## 5 17019001203 Census Tract 12.03, Champaign County, Illinois 1594
## 6 17019005800 Census Tract 58, Champaign County, Illinois 823
## housevalueM totpE totpM tothouseE tothouseM med.incomeE med.incomeM
## 1 96 2473 258 1163 66 42750 7229
## 2 99 3898 222 1831 93 54128 4587
## 3 19 4740 548 2277 101 7166 1427
## 4 106 3528 359 1708 73 38036 5422
## 5 117 4788 362 2033 60 73463 5083
## 6 87 4013 392 1809 87 50160 14151
## income.gt75E income.gt75M for.bornE for.bornM house.ageE house.ageM
## 1 92 51 21 24 1949 7
## 2 275 58 232 88 1964 4
## 3 34 44 783 236 1988 5
## 4 79 53 512 205 1964 13
## 5 675 176 324 133 1976 1
## 6 576 99 741 206 1939 NA
## month.house.costE month.house.costM med.gross.rentE med.gross.rentM workhomeE
## 1 679 85 639 134 45
## 2 774 36 684 137 69
## 3 918 143 912 139 103
## 4 724 73 763 31 50
## 5 1135 58 1108 171 93
## 6 973 77 947 111 81
## workhomeM owneroccupiedE owneroccupiedM totalbedsE totalbedsM broadbandE
## 1 27 721 96 1163 66 739
## 2 33 1292 99 1831 93 1278
## 3 77 11 19 2277 101 1484
## 4 40 691 106 1708 73 855
## 5 53 1594 117 2033 60 1704
## 6 36 823 87 1809 87 1322
## broadbandM geometry
## 1 94 MULTIPOLYGON (((-91.3937 39...
## 2 104 MULTIPOLYGON (((-89.23894 4...
## 3 187 MULTIPOLYGON (((-88.24177 4...
## 4 138 MULTIPOLYGON (((-88.25797 4...
## 5 106 MULTIPOLYGON (((-88.29524 4...
## 6 138 MULTIPOLYGON (((-88.21775 4...I then use the same tutorial and the mutate function to create
- the percentage of people earning over $75K (e.g. per.income.gt75E / totpE)
- the percentage of people who work from home (workhomeE / totpE)
- the percentage of houses that are owner occupied (owneroccupiedE / tothouseE)
Here is the summary of the data I downloaded with the new columns added in. You can see that there are 3123 census tracts in Illinois and that the data is clearly marked, with 31 columns of data. As before, each column ending in E means the estimate of the value in each census tract and the column ending in M means the margin of error. The unit of observation is a census tract in Illinois
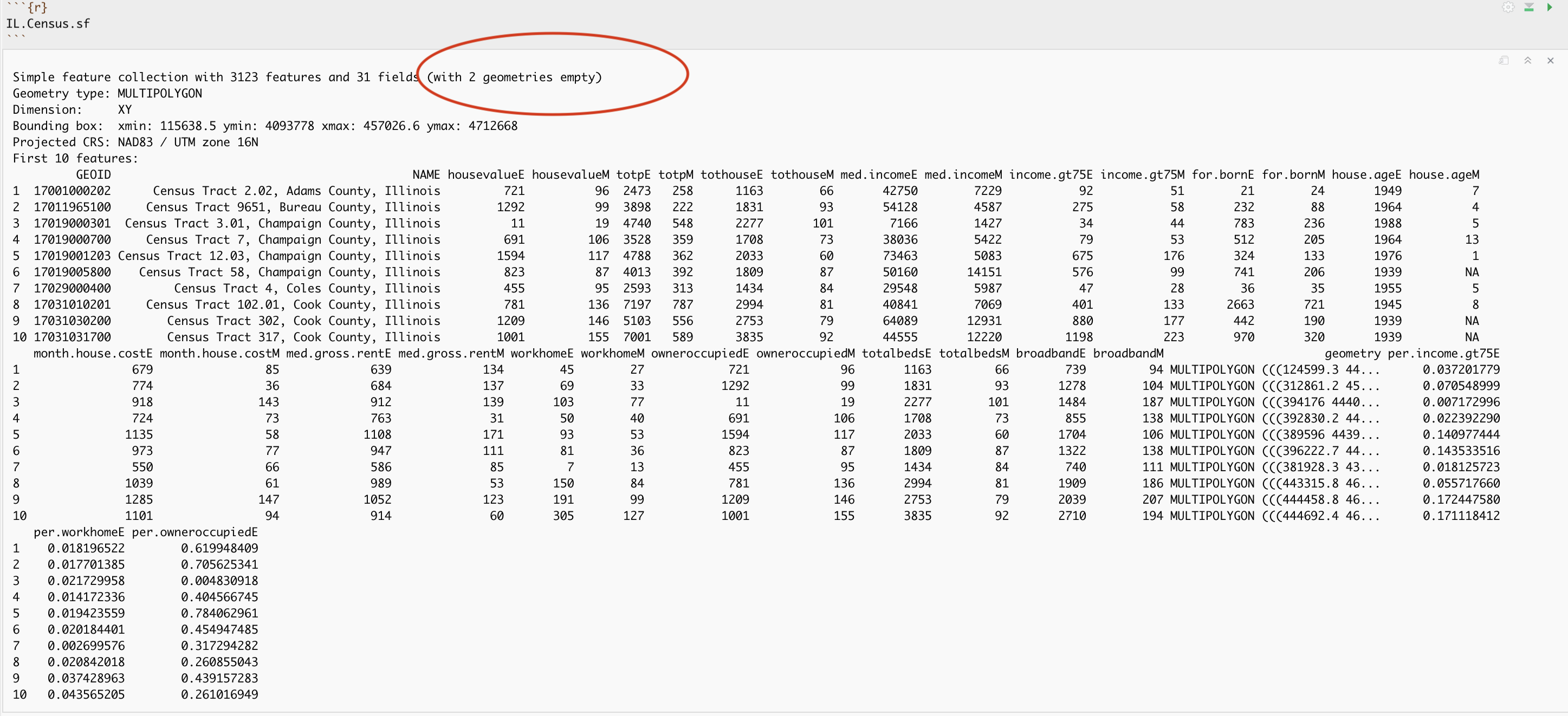
Dealing with empty polygons
Now.. one quirk of R is that it **hates* empty polygons and if you look at the screenshot above there are two of them here. IF YOU GET ERRORS PLOTTING, I BET THIS IS WHAT IS HAPPENING.
In our case, empty polygons means empty census tracts. These might be census tracts where no-one lives, or more likely, a quirk of the data collection process. Let’s take a look at them.
We can check this with the st_is_empty() command:
which_tracts_empty <- st_is_empty(IL.Census.sf)
empty_tracts <- dplyr::filter(IL.Census.sf,which_tracts_empty==TRUE)
empty_tracts## Simple feature collection with 2 features and 31 fields (with 2 geometries empty)
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: NA ymin: NA xmax: NA ymax: NA
## Geodetic CRS: NAD83
## GEOID NAME housevalueE housevalueM
## 1 17097990000 Census Tract 9900, Lake County, Illinois 0 11
## 2 17031990000 Census Tract 9900, Cook County, Illinois 0 11
## totpE totpM tothouseE tothouseM med.incomeE med.incomeM income.gt75E
## 1 0 11 0 11 NA NA 0
## 2 0 11 0 11 NA NA 0
## income.gt75M for.bornE for.bornM house.ageE house.ageM month.house.costE
## 1 11 0 11 NA NA NA
## 2 11 0 11 NA NA NA
## month.house.costM med.gross.rentE med.gross.rentM workhomeE workhomeM
## 1 NA NA NA 0 11
## 2 NA NA NA 0 11
## owneroccupiedE owneroccupiedM totalbedsE totalbedsM broadbandE broadbandM
## 1 0 11 0 11 0 11
## 2 0 11 0 11 0 11
## geometry per.income.gt75E per.workhomeE per.owneroccupiedE
## 1 MULTIPOLYGON EMPTY NaN NaN NaN
## 2 MULTIPOLYGON EMPTY NaN NaN NaNOK so it’s tracts 9900 in Cook county and lake county Illinois. Let’s google that… and the results suddenly make sense!
I feel satisfied that removing these polygons won’t mess up my study. So I’m going to go ahead and remove them and overwrite the results. E.g. I apply the filter command to IL.Census.sf, asking it to only choose rows where which_tracts_empty is FALSE, then save the result to IL.Census.sf.
Note, here I use the [ ] way of subsetting - filter messes up the spatial formatting
tracts_empty <- st_is_empty(IL.Census.sf)
# ALL columns but only rows where they are NOT empty
IL.Census.sf <- IL.Census.sf[which(tracts_empty==FALSE), ] Now.. let’s try again. Yep, we have removed the empty fields.
IL.Census.sf## Simple feature collection with 3121 features and 31 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -91.51308 ymin: 36.9703 xmax: -87.49476 ymax: 42.50848
## Geodetic CRS: NAD83
## First 10 features:
## GEOID NAME housevalueE
## 1 17001000202 Census Tract 2.02, Adams County, Illinois 721
## 2 17011965100 Census Tract 9651, Bureau County, Illinois 1292
## 3 17019000301 Census Tract 3.01, Champaign County, Illinois 11
## 4 17019000700 Census Tract 7, Champaign County, Illinois 691
## 5 17019001203 Census Tract 12.03, Champaign County, Illinois 1594
## 6 17019005800 Census Tract 58, Champaign County, Illinois 823
## 7 17029000400 Census Tract 4, Coles County, Illinois 455
## 8 17031010201 Census Tract 102.01, Cook County, Illinois 781
## 9 17031030200 Census Tract 302, Cook County, Illinois 1209
## 10 17031031700 Census Tract 317, Cook County, Illinois 1001
## housevalueM totpE totpM tothouseE tothouseM med.incomeE med.incomeM
## 1 96 2473 258 1163 66 42750 7229
## 2 99 3898 222 1831 93 54128 4587
## 3 19 4740 548 2277 101 7166 1427
## 4 106 3528 359 1708 73 38036 5422
## 5 117 4788 362 2033 60 73463 5083
## 6 87 4013 392 1809 87 50160 14151
## 7 95 2593 313 1434 84 29548 5987
## 8 136 7197 787 2994 81 40841 7069
## 9 146 5103 556 2753 79 64089 12931
## 10 155 7001 589 3835 92 44555 12220
## income.gt75E income.gt75M for.bornE for.bornM house.ageE house.ageM
## 1 92 51 21 24 1949 7
## 2 275 58 232 88 1964 4
## 3 34 44 783 236 1988 5
## 4 79 53 512 205 1964 13
## 5 675 176 324 133 1976 1
## 6 576 99 741 206 1939 NA
## 7 47 28 36 35 1955 5
## 8 401 133 2663 721 1945 8
## 9 880 177 442 190 1939 NA
## 10 1198 223 970 320 1939 NA
## month.house.costE month.house.costM med.gross.rentE med.gross.rentM
## 1 679 85 639 134
## 2 774 36 684 137
## 3 918 143 912 139
## 4 724 73 763 31
## 5 1135 58 1108 171
## 6 973 77 947 111
## 7 550 66 586 85
## 8 1039 61 989 53
## 9 1285 147 1052 123
## 10 1101 94 914 60
## workhomeE workhomeM owneroccupiedE owneroccupiedM totalbedsE totalbedsM
## 1 45 27 721 96 1163 66
## 2 69 33 1292 99 1831 93
## 3 103 77 11 19 2277 101
## 4 50 40 691 106 1708 73
## 5 93 53 1594 117 2033 60
## 6 81 36 823 87 1809 87
## 7 7 13 455 95 1434 84
## 8 150 84 781 136 2994 81
## 9 191 99 1209 146 2753 79
## 10 305 127 1001 155 3835 92
## broadbandE broadbandM geometry per.income.gt75E
## 1 739 94 MULTIPOLYGON (((-91.3937 39... 0.037201779
## 2 1278 104 MULTIPOLYGON (((-89.23894 4... 0.070548999
## 3 1484 187 MULTIPOLYGON (((-88.24177 4... 0.007172996
## 4 855 138 MULTIPOLYGON (((-88.25797 4... 0.022392290
## 5 1704 106 MULTIPOLYGON (((-88.29524 4... 0.140977444
## 6 1322 138 MULTIPOLYGON (((-88.21775 4... 0.143533516
## 7 740 111 MULTIPOLYGON (((-88.37305 3... 0.018125723
## 8 1909 186 MULTIPOLYGON (((-87.68465 4... 0.055717660
## 9 2039 207 MULTIPOLYGON (((-87.67062 4... 0.172447580
## 10 2710 194 MULTIPOLYGON (((-87.6675 41... 0.171118412
## per.workhomeE per.owneroccupiedE
## 1 0.018196522 0.619948409
## 2 0.017701385 0.705625341
## 3 0.021729958 0.004830918
## 4 0.014172336 0.404566745
## 5 0.019423559 0.784062961
## 6 0.020184401 0.454947485
## 7 0.002699576 0.317294282
## 8 0.020842018 0.260855043
## 9 0.037428963 0.439157283
## 10 0.043565205 0.261016949Check/change the map projection
I now check the map projection. Here I can see that we assigned our data to be in Lat/Long, with a datum (the shape of the world) of WGS 84 and EPSG/CRS code 4326.
raster::projection(IL.Census.sf)## [1] "+proj=longlat +datum=NAD83 +no_defs"I want to make sure that this is a more appropriate map projection, knowing that Lat/Lon is sometimes less appropriate for zoomed in data, so I look up the UTM projection for Illinois (Tutorial 11 projections:), which turns out to have a CRS code of 26916.
I convert it to UTM, using the same method you used in Lab 6 and in Tutorial 11b projections in R:. I’m not including the code as you have done this before and its in the tutorials/lab 6.
Now you can see we have set our projection to UTM zone 16.
raster::projection(IL.Census.sf)## [1] "+proj=utm +zone=16 +datum=NAD83 +units=m +no_defs"I then had a quick look at the data in tmap to make sure it looked good, using the tutorials here (and in tutorial 11b) https://mgimond.github.io/Spatial/mapping-data-in-r.html#tmap.
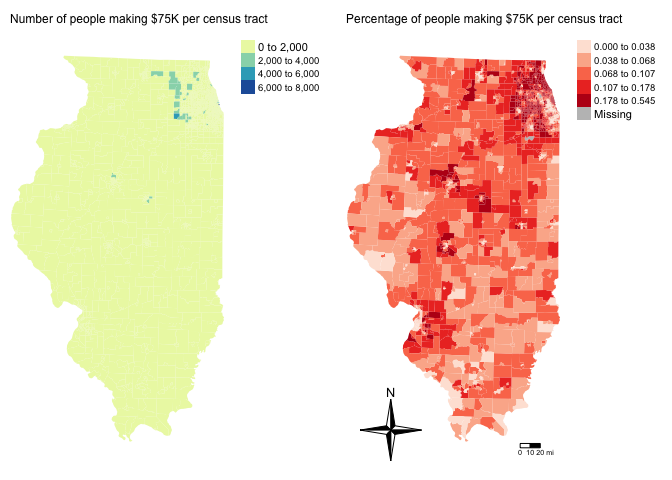
Calculate the population density per unit area**
Newly updated in tutorial 6, we can also calculate the spatial area of each census tract using the st_area() command.
#Finding the area of each county
IL.tract.area.m2 <- st_area(IL.Census.sf)
# This is in metres^2. Convert to Km sq
IL.tract.area.km2 <- set_units(IL.tract.area.m2, "km^2")
IL.tract.area.km2 <- as.numeric(IL.tract.area.km2)This makes it easy to add a population density column
IL.Census.sf <- mutate(IL.Census.sf, pop.densityE = totpE/IL.tract.area.km2)
# and the housing density
IL.Census.sf <- mutate(IL.Census.sf, house.densityE = tothouseE/IL.tract.area.km2)Let’s use tmap to take a look. Note if you see this error, you have mistyped a column name - I forgot to put in the totpE.
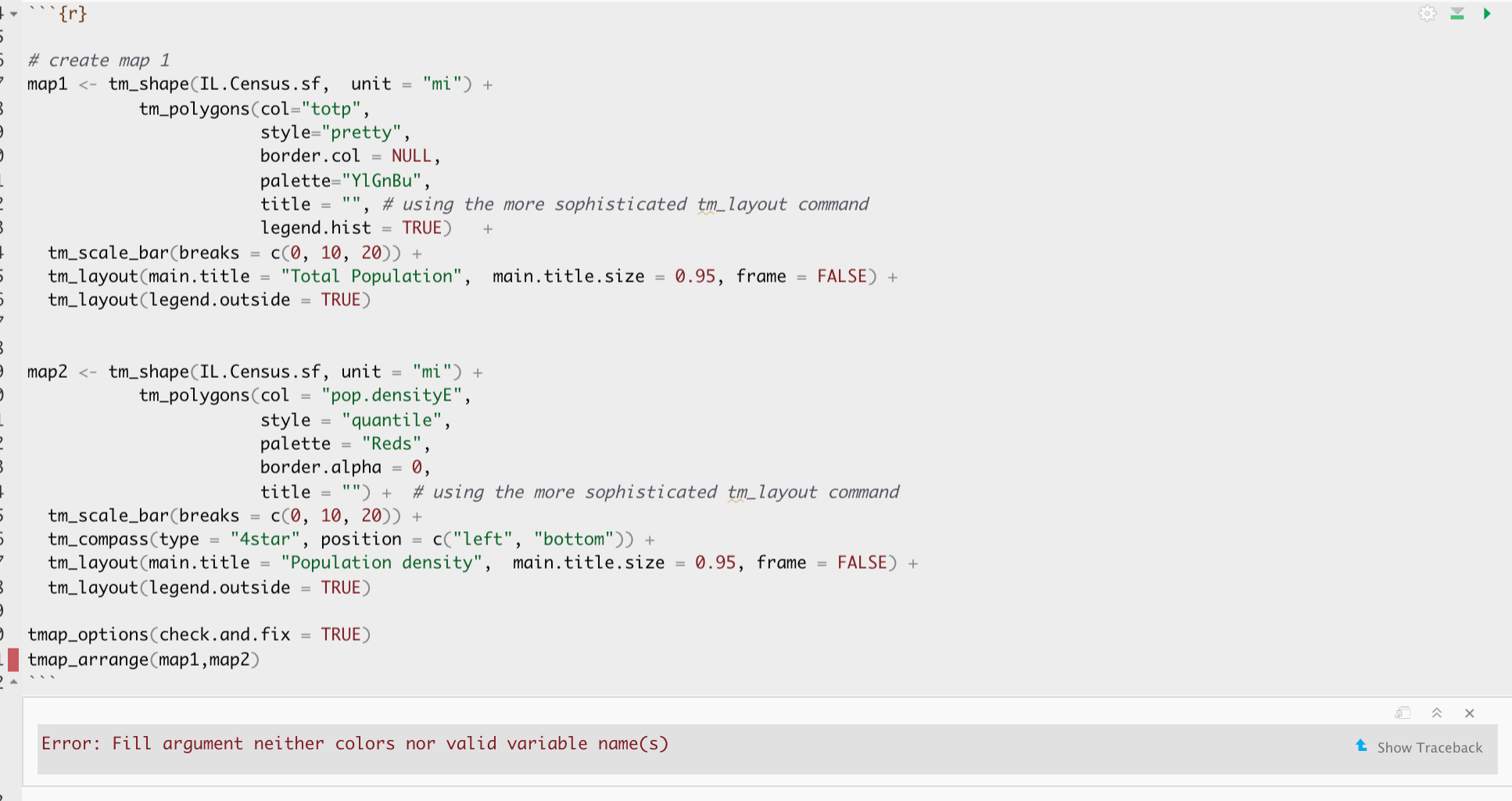
You have asked it to plot a column that doesn’t exist
Let’s try again:
# create map 1
map3 <- tm_shape(IL.Census.sf, unit = "mi") +
tm_polygons(col="totpE",
style="pretty",
border.col = NULL,
palette="YlGnBu",
title = "", # using the more sophisticated tm_layout command
legend.hist = TRUE) +
tm_scale_bar(breaks = c(0, 10, 20)) +
tm_layout(main.title = "Total Population", main.title.size = 0.95, frame = FALSE) +
tm_layout(legend.outside = TRUE)
# create map 1
map4 <- tm_shape(IL.Census.sf, unit = "mi") +
tm_polygons(col = "pop.densityE",
style = "quantile",
palette = "Reds",
border.alpha = 0,
title = "") + # using the more sophisticated tm_layout command
tm_scale_bar(breaks = c(0, 10, 20)) +
tm_compass(type = "4star", position = c("left", "bottom")) +
tm_layout(main.title = "Population density", main.title.size = 0.95, frame = FALSE) +
tm_layout(legend.outside = TRUE)
tmap_options(check.and.fix = TRUE)
# and print
tmap_arrange(map3,map4)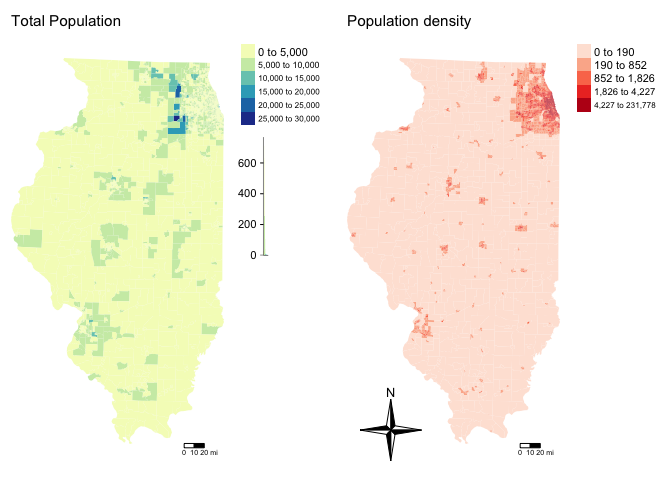
Zooming in
This map looks at all of Illinois. But we want to look at the area just around Chicago. There are two ways we could do this.
Cropping to a lat long box [ just for show DO NOT DO THIS]
DO NOT DO THIS: The first way is to simply “draw” a new lat/long box for the data using the raster crop function. Because the data is in the UTM map projection, I worked out my new bounding box coordinates here: https://www.geoplaner.com/
# My new region from https://www.geoplaner.com/
Crop.Region <- as(extent(361464,470967,4552638,4701992), "SpatialPolygons")
# Make IL.census an sp format
IL.Census.sp <- as(IL.Census.sf,"Spatial")
# And force the projection to be the same as the Illinois data
proj4string(Crop.Region) <- CRS(proj4string(IL.Census.sp))
# Subset the polygons to my new region
IL.Census.sp.BOX <- crop(IL.Census.sp, Crop.Region, byid=TRUE)
# and convert back to sf
IL.Census.sf.BOX <- st_as_sf(IL.Census.sp.BOX)
# Finally plot
tm_shape(IL.Census.sf.BOX, unit = "mi") +
tm_polygons(col = "pop.densityE", style = "quantile",
palette = "Reds", border.alpha = 0,
title = "Population Density")+
tm_layout(legend.outside = TRUE) 
Loading city boundary data (do this)
Instead of a box, we might better want to crop to administrative boundaries. We can download these using the Tigris package.
Tigris has thousands of boundary data-sets that you can explore. For a tutorial, see here [https://crd150.github.io/lab4.html#tigris_package] and here [https://github.com/walkerke/tigris]
For now, lets download the Chicago metropolitan area data then select Chicago
cb.sf <- core_based_statistical_areas(cb = TRUE, year=2017)
Chicago.metro.sf <- filter(cb.sf, grepl("Chicago", NAME))
# and set the projection to be identical to the census data
Chicago.metro.sf <- st_transform(Chicago.metro.sf,crs=st_crs(IL.Census.sf))Or… we can look at the city limits
# Choose all the places in Illinois
pl <- places(state = "IL", cb = TRUE, year=2017)
# and find the ones called Chicago
Chicago.city.sf <- filter(pl, NAME == "Chicago")
# and set the projection to be identical to the census data
Chicago.city.sf <- st_transform(Chicago.city.sf,crs=st_crs(IL.Census.sf))and, just so you can see what I have done..
tmap_mode("view")
map.metro <- qtm(st_geometry(Chicago.metro.sf),fill = NULL,border="red")
map.city <- qtm(st_geometry(Chicago.city.sf),fill = NULL,border="red")
tmap_arrange(map.metro,map.city)
We can now crop our census data to this specific area using the ms_clip function.
# subset the Illinois census data with the Chicago city limits
Chicago.Census.sf <- ms_clip(target = IL.Census.sf,
clip = Chicago.city.sf,
remove_slivers = TRUE)Let’s remake that map, remember to play with the style option if your color scale isn’t useful
# create map 1
map7 <- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col="pop.densityE",
style="quantile",
border.col = NULL, title="",
palette="viridis") +
tm_layout(title = "Population Density", title.size = 0.95, frame = FALSE)+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE)
# create map 1
map8 <- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "per.income.gt75E",
style = "pretty",
palette = "YlGnBu",
border.alpha = 0,
title = "") + # using the more sophisticated tm_layout command
tm_scale_bar(breaks = c(0, 10, 20)) +
tm_layout(frame = FALSE, title = "Percentage making over $75K", main.title.size = 0.95)+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE)
tmap_options(check.and.fix = TRUE)
# and print
suppressMessages(tmap_arrange(map7,map8))
Challenge B1:
- Step 1:
Set up your lab script to look good. I’m going to give you less advice on structure, so remember - this is how we grade formatting (see tutorial 4 for reminders on how to do this):
- We will start by awarding full marks and dock marks for mistakes.LOOK AT YOUR HTML FILE IN YOUR WEB-BROWSER BEFORE YOU SUBMIT
- TO GET 13/13 : All the below PLUS your mathematical equations use the formal latex equation format () & you use subscripts/superscript as appropriate (2.14) for your H0 and H1s ()
- TO GET 11/13 : all of these:
- Your document is neat and easy to read.
- You have a working table of contents and use headings and subheadings
- Answers are easy to find and paragraphs are clear (e.g. you left spaces between lines)
- You have written in full sentences, it is clear what your answers are referring to.
- You have used the spell check.
- You have used YAML code to make your work look professional (themes, tables of contents etc)
- You have explained what you are doing in your code in the text below/above.
- You do not have the tutorial example in your writeup.
- Your document is neat and easy to read.
- We will start by awarding full marks and dock marks for mistakes.LOOK AT YOUR HTML FILE IN YOUR WEB-BROWSER BEFORE YOU SUBMIT
- Step 2:
Choose a US State of your choice (NOT New York). Use the tutorials above, Tutorial 6Ec get_ACS: and and your lab 6 to download the following ACS survey data for the 5 year 2017 ACS survey. Remember to name your variables usefully.
- housevalue (“B25075_001”) : house value
- totp (“B05012_001”) : total population
- tothouse (“B25001_001”) : total housing units
- med.income (“B19013_001”) : median income
- income.gt75 (“B06010_011”) : number of people making > 75000 USD
- for.born (“B05012_003”) : number of foreign born people
- house.age (“B25035_001”) : average house age
- month.house.cost (“B25105_001”) : monthly house expenditures
- med.gross.rent (“B25064_001”) : median rent
- workhome (“B08101_049”) : number who work from home
- owneroccupied (“B25003_002”) : total owner occupied
- broadband (“B28002_004”) : total with access to broadband
- The Gini Index of income inequality: B19083_001
- The total number of people who report having a bachelors degree: B06009_005
- Any other variables you are interested in (optional)
- Step 3:
Calculate the percentage of people who work from home, the percentage of people with access to broadband, the housing density per per km2 in each census tract and the population density per km2 in each census tract - and save them as new columns (same as my example)
- Step 4:
Remember to set your data to an appropriate map projection, then choose a major city in your State.
Following the tutorial above, subset your data to its borders. YOUR NEW DATASET SHOULD HAVE AT LEAST 20 POINTS/ROWS. IF NOT, CHOOSE A BIGGER CITY.
- Step 5:
Explore the data - have a look at some maps, and in your final report include one or two high quality maps of interesting variables.
In your report, talk about some interesting patterns and relationships that you see and relate it to the real life city. If you don’t know the city well, google it! Make sure the data make sense.
C: Autocorrelation, Moran and LISA
Moran’s I rerun
I’m now going to see if one of my variables is auto-correlated - the percentage of people earning over $75K. I’m doing this here as well as the last lab because census data can throw up errors and I want you to see them.
First, following on from Lab 6, I calculate the spatial weights matrix (I chose Queens). As described in https://crd150.github.io/lab6.html#Spatial_data_wrangling, I have first established who our neighbors are by creating an nb object using poly2nb().
The next step is to assign weights to each neighbor relationship. The weight determines how much each neighbor counts, where I need to employ the nb2listw() command from the spdep package, which will give me a spatial weights object.
In the command, I first put in your neighbor nb object (Chicago.matrix.rook) and then define the weights style = “W”. Here, style = “W” indicates that the weights for each spatial unit are standardized to sum to 1 (this is known as row standardization). For example, if census tract 1 has 3 neighbors, each of the neighbors will have a weight of 1/3. This allows for comparability between areas with different numbers of neighbors.
The zero.policy = TRUE argument tells R to ignore cases that have no neighbors. How can this occur? See this website for an example. It shows tracts in Los Angeles county. You’ll notice two tracts that are not geographically adjacent to other tracts - they are literally islands (Catalina and San Clemente). So, if you specify queen adjacency, these islands would have no neighbors. If you conduct a spatial analysis of Los Angeles county tracts in R, most functions will spit out an error indicating that you have polygons with no neighbors. To avoid that, specify zero.policy = TRUE, which will ignore all cases without neighbors. In Chicago, I don’t care so much, but it’s here in case your city needs it.
Chicago.Census.sp <- as(Chicago.Census.sf,"Spatial")
# calculate the spatial weights matrix, I put zero.policy = T to capture missing data
Chicago.matrix.rook <-poly2nb(Chicago.Census.sp, queen=T)
# calculate the spatial weights
chicago.weights.queen <- nb2listw(Chicago.matrix.rook, style='B', zero.policy = T)
# looks interlinked!
plot(chicago.weights.queen, coordinates(Chicago.Census.sp), col='black', lwd=1, cex=.2)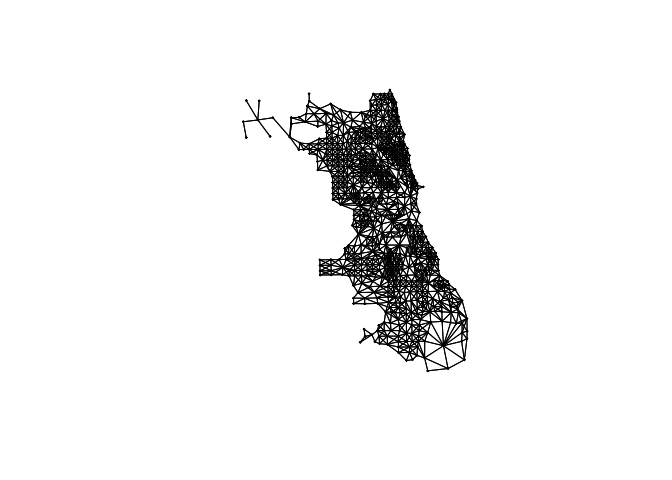
In fact we can see just how complicated the matrix is by looking at the summary of our weights:
Chicago.matrix.rook## Neighbour list object:
## Number of regions: 804
## Number of nonzero links: 5260
## Percentage nonzero weights: 0.8137175
## Average number of links: 6.542289I then conduct a Moran’s I analysis. But I get an error! It says I have missing values in “x” AKA in my percentage income column.

There are missing values in your column of choice
Let me check:
summary(Chicago.Census.sf$per.income.gt75E)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00000 0.03035 0.06649 0.11028 0.16341 0.54485 3Yes - three polygons didn’t calculate properly. Let’s take a look:
Chicago.Census.sf[is.na(Chicago.Census.sf$per.income.gt75E)==TRUE,]## Simple feature collection with 3 features and 33 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 422143.8 ymin: 4625415 xmax: 448004.7 ymax: 4650851
## Projected CRS: NAD83 / UTM zone 16N
## GEOID NAME housevalueE
## 392 17031980100 Census Tract 9801, Cook County, Illinois 0
## 747 17031980000 Census Tract 9800, Cook County, Illinois 0
## 780 17031381700 Census Tract 3817, Cook County, Illinois 0
## housevalueM totpE totpM tothouseE tothouseM med.incomeE med.incomeM
## 392 11 0 11 0 11 NA NA
## 747 11 0 11 0 11 NA NA
## 780 11 0 11 0 11 NA NA
## income.gt75E income.gt75M for.bornE for.bornM house.ageE house.ageM
## 392 0 11 0 11 NA NA
## 747 0 11 0 11 NA NA
## 780 0 11 0 11 NA NA
## month.house.costE month.house.costM med.gross.rentE med.gross.rentM
## 392 NA NA NA NA
## 747 NA NA NA NA
## 780 NA NA NA NA
## workhomeE workhomeM owneroccupiedE owneroccupiedM totalbedsE totalbedsM
## 392 0 11 0 11 0 11
## 747 0 11 0 11 0 11
## 780 0 11 0 11 0 11
## broadbandE broadbandM per.income.gt75E per.workhomeE per.owneroccupiedE
## 392 0 11 NA NA NA
## 747 0 11 NA NA NA
## 780 0 11 NA NA NA
## pop.densityE house.densityE geometry
## 392 0 0 MULTIPOLYGON (((436663.3 46...
## 747 0 0 MULTIPOLYGON (((424205.8 46...
## 780 0 0 MULTIPOLYGON (((447759.2 46...Hmm.. when we subset to our city borders, it appears we’ve put those lake tracts back in. Let’s remove AGAIN - and redo our weights matrix. This time I’m just going to remove any census tract with zero population:
Chicago.Census.sf <- Chicago.Census.sf[Chicago.Census.sf$totpE > 0 , ]and let’s remake our matrix
Chicago.Census.sp <- as(Chicago.Census.sf,"Spatial")
# calculate the spatial weights matrix, I put zero.policy = T to capture missing data
Chicago.matrix.rook <-poly2nb(Chicago.Census.sp, queen=T)
# calculate the spatial weights
chicago.weights.queen <- nb2listw(Chicago.matrix.rook, style='B', zero.policy = T)
## and calculate the Moran's plot
moran.plot(Chicago.Census.sf$per.income.gt75E,
listw= chicago.weights.queen,
xlab = "Percentage income > $75K",
ylab = "Avergae Percentage income > $75K of neighbours",
zero.policy = T)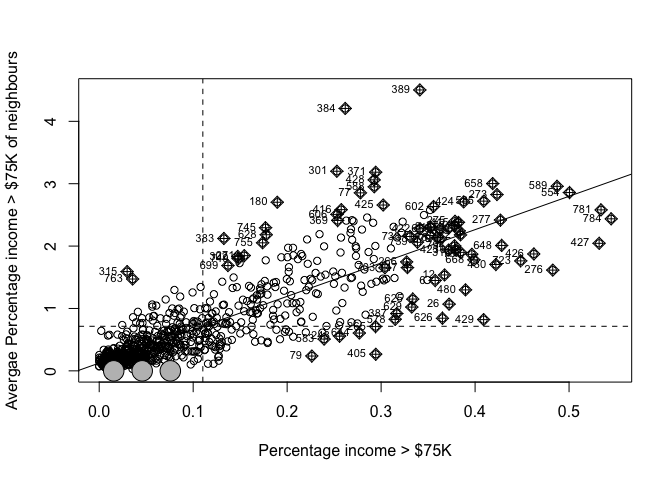
It looks clustered.. (which agrees with the map I made). Let’s do a test. I’ll let you interpret it!
moran.test(Chicago.Census.sf$per.income.gt75E,
chicago.weights.queen,
zero.policy = T) ##
## Moran I test under randomisation
##
## data: Chicago.Census.sf$per.income.gt75E
## weights: chicago.weights.queen n reduced by no-neighbour observations
##
##
## Moran I statistic standard deviate = 42.341, p-value < 2.2e-16
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.8235189240 -0.0012547051 0.0003794437
LISA , Local Moran’s I
Moran’s I is just a global statistic, it would be useful to know where the data was clustered or not. LISA is a local version of Moran’s I. I don’t know why, but this is the one thing that no-one has made a pretty function for. You get the “show me something new” if you can do it for your data:
First, let’s create all the local moran values
FOR THIS TO WORK YOU NEED TO UPDATE THE SPDEP PACKAGE TO VERSION 1.11. The easiest way is to reinstall it - go to the package menu, then click install and find spdep and say yes to the questions. THEN RESTART R STUDIO AND RERUN YOUR CODE FROM THE BEGINNING
#---------------------------------------------------
# First, we need an sp version of our data
#---------------------------------------------------
Chicago.Census.sp <- as(Chicago.Census.sf,"Spatial")
#---------------------------------------------------
# We can either create the Raw LISA values using the theoretical approach or Monte Carlo
#
# - Padjust allows us to account for mulitple testing issues.
# - adjust.x allows us to omit polygons with no neighbours as needed
# - zero.policy allows us to keep but ignore polygons with no neighbours
# - nsim: number of simulations, If this crashes the cloud try reducing to say 50
#---------------------------------------------------
LocalMoran_Output <- localmoran_perm(x = Chicago.Census.sp$per.income.gt75E,
listw = chicago.weights.queen,
nsim=499,
p.adjust.method = "none",
adjust.x = TRUE,
zero.policy = T)
#---------------------------------------------------
# The column names are less intuitive to newbies, so let's rename them
# (to see the originals, type ?localmoran into the console)
# The skew and kurtosis are because the histogram of IRP I might not look normal
# To do this I force the output to be a standard dataframe
#---------------------------------------------------
LocalMoran_Table <- as.data.frame(LocalMoran_Output)
names(LocalMoran_Table) <- c("Observed_LocalI", "IRP_estimate_LocalI", "Variance_I",
"ZScore_I", "PValue_Theoretical", "PValue_MonteCarlo",
"Skew_I","Kurtosis_I")
#---------------------------------------------------
# Merge with our data
#---------------------------------------------------
Chicago.Census.sp <- cbind(Chicago.Census.sp,LocalMoran_Table)
#---------------------------------------------------
# It turns out that the quadrants are secretly stored in the output,
# so we don't even have to manually calculate them
#---------------------------------------------------
Chicago.Census.sp$LISA_Quadrant <- attr(LocalMoran_Output,"quadr")$mean
#---------------------------------------------------
# and add transparency as a proxy for p=value [WORK IN PROGRESS - IGNORE]
#Chicago.Census.sp$pvalue_transparency <- 0.9
#Chicago.Census.sp$pvalue_transparency[Chicago.Census.sp$PValue_MonteCarlo < 0.05] <- 0.5
#Chicago.Census.sp$pvalue_transparency[Chicago.Census.sp$PValue_MonteCarlo >= 0.01] <- 0.2
#Chicago.Census.sp$pvalue_transparency[Chicago.Census.sp$PValue_MonteCarlo >= 0.005] <- 0
#---------------------------------------------------
#---------------------------------------------------
# Remove polygons that are unlikely to be significant
# YOU GET TO CHOOSE THE THRESHOLD HERE
#---------------------------------------------------
critical_threshold <- 0.05
#---------------------------------------------------
# Find the rows where your p-value is > your threshold
#---------------------------------------------------
RowsOverThreshold <- which(Chicago.Census.sp$PValue_MonteCarlo >critical_threshold)
#---------------------------------------------------
# Make the column a character to make life easy
# Then rename the quadrant in those rows p>0.05, or
# whatever your threshold is
#---------------------------------------------------
Chicago.Census.sp$LISA_Quadrant_Plot <- as.character(Chicago.Census.sp$LISA_Quadrant)
Chicago.Census.sp$LISA_Quadrant_Plot[RowsOverThreshold] <- paste("P>",critical_threshold,sep="")
#---------------------------------------------------
# Make a factor again
#---------------------------------------------------
Chicago.Census.sp$LISA_Quadrant_Plot <- factor(Chicago.Census.sp$LISA_Quadrant_Plot,
levels= c("High-High",
"High-Low",
"Low-High",
"Low-Low", paste("P>",critical_threshold,sep="")))
#---------------------------------------------------
# and finally change our data back to sf
#---------------------------------------------------
Chicago.Census.sf <- st_as_sf(Chicago.Census.sp)Now let’s make a pretty plot:
#---------------------------------------------------
# And make a plot
#---------------------------------------------------
mapLISA <- tm_shape(Chicago.Census.sf) +
tm_fill( "LISA_Quadrant_Plot",id="NAME", alpha=.6,
palette= c("#ca0020","#f4a582","#92c5de","#0571b0","white"), title="") +
tm_legend(text.size = 1) +
tm_borders(alpha=.5) +
tm_layout( frame = FALSE, title = paste("LISA: % earning>$75K,sig= ",critical_threshold))
#---------------------------------------------------
# plot against the raw values
#---------------------------------------------------
mapRaw <- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "per.income.gt75E",
style = "pretty",
palette = "YlGnBu",
border.alpha = 0,
title = "",alpha=.6) +
tm_layout(frame = FALSE, title = "Percentage making over $75K", main.title.size = 0.95)+
tm_borders(alpha=.5)+
tm_layout(legend.outside = TRUE)
tmap_options(check.and.fix = TRUE)
tmap_mode("view")
tmap_arrange(mapRaw,mapLISA)tmap_mode("plot")Here, we can see that there are many census tracts with lots of people making over $ 75K, surrounded by neighbours that make the same. Equally there are many neighbourhoods in Chicago where there are few “high earning” residents. So this shows that yes, there is absolutely clustering overall in Chicago in this variable, but this gives us some more insight into where…
It also allows us to examine outliers. For example, this low-high area
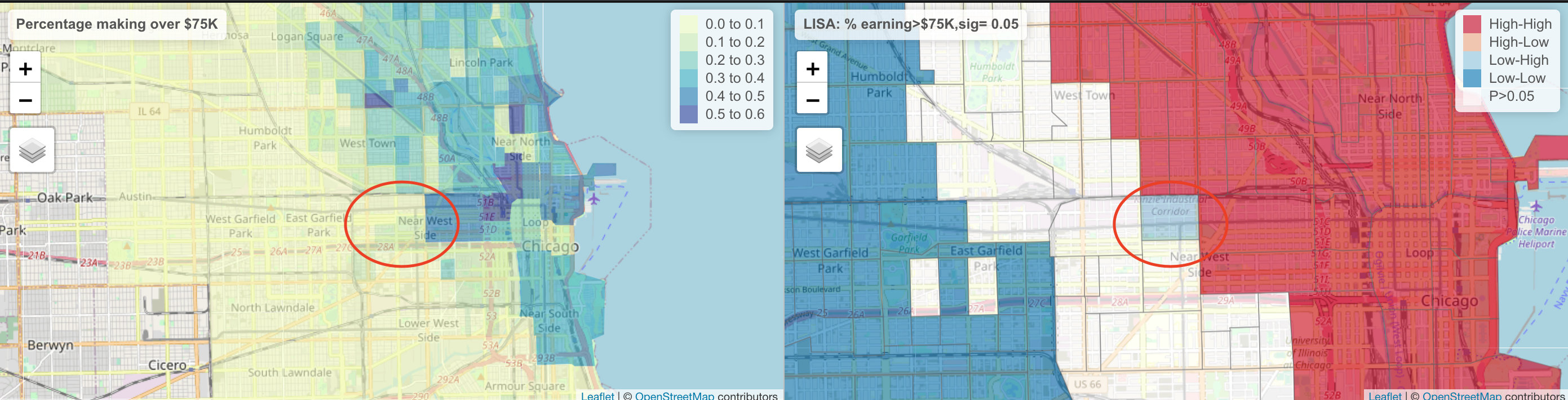
The stark difference here makes me want to explore this further for process. Maybe there is an industrial area here - maybe this is a legacy of Chicago’s massive legacy of redlining and housing discrimination (https://www.bloomberg.com/news/articles/2020-09-30/mapping-the-disparities-of-chicago-s-unequal-pandemic). Maybe there is a single luxury housing block next door. But it is definitely interesting! This is where your projects could really shine.
Challenge C1:
- Step 6:
Use the tutorial above to conduct a Moran’s global analysis for the percentage of people who work from home column for your city. Write out a full hypothesis test in the text and use the Moran’s I test output to inform your conclusions
- Step 7:
OPTIONAL. For 4 show me something new points, get the LISA analysis up and running - and interpret the output in the text.
D Regression
Basics
Now we have some data, let’s do some regression analysis on it. Building on the lectures, first let’s look at the basics.
I would like to understand whether the percentage of people making more than $75,000 in each census tract in Chicago is influenced by some of the other demographic factors that I downloaded. First, I could look at the general correlation between each one of my variables (e.g. how well does a linear model fit the data).
For example, the correlation between the median income in each census tract and the percentage making > $75,000 can be obtained using the cor command. Here we can see that the correlation coefficient is 0.86.
cor(Chicago.Census.sf$med.incomeE,
Chicago.Census.sf$per.income.gt75E,use="pairwise.complete.obs")## [1] 0.8635787Given that more highly paid people should bump up the median income, unsurprisingly there is a reasonable relationship between the two variables! Let’s quickly check it made sense to do this - e.g that it looks reasonably linear.
plot(Chicago.Census.sf$med.incomeE,Chicago.Census.sf$per.income.gt75E)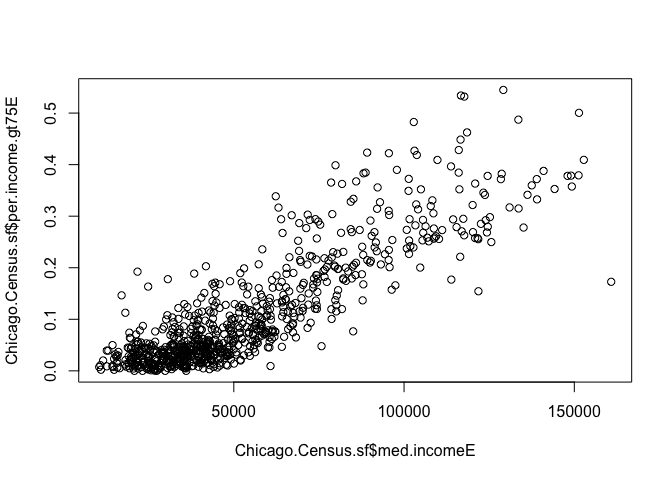
In fact, the cor command can go even further and check the correlation between many variables in our dataset that we care about:
# this will only work for columns containing numbers, so I am explicitly naming the ones I want
# the st_drop_geometry command makes it not spatial data for a second
corr<-cor(st_drop_geometry(Chicago.Census.sf[,c("housevalueE","pop.densityE","house.densityE",
"per.income.gt75E","med.incomeE","totalbedsE")]),use="pairwise.complete.obs")
# Now we can make a cool plot of this, check out other method
corrplot(corr,method="number",number.cex=.5)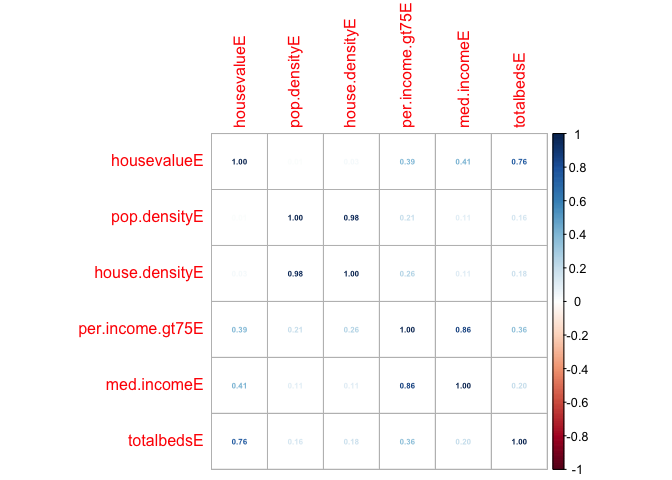
Three regression models
We are now going to look at THREE versions of a model to assess whether people who make over $75000 are more likely to live in places with higher population density e.g. “downtown”. We are also going to look to see if the residuals (what is left over) from our model has spatial autocorrelation (bad).
I am using a real messy example so that you can see things like outlier removal.
Model 1: Simple Linear Regression
Here we just look to see if our response (people who make over $75000) can be predicted by a SINGLE variable with no reference to geography: Simple Linear Regression.
We can make a basic scatterplot using the plot command. Alternatively, we can make an interactive plot using ggplot.
I want to explore whether people who make over $75000 are more likely to live in places with higher population density e.g. “downtown”.
BUT! The ecological fallacy means we can’t fully do this. ALL WE CAN TEST IS: Do census tracts which contain a higher population density ALSO contain a higher percentage of people who make > $75000..
First the correlation coefficient and the plot
cor(Chicago.Census.sf$pop.densityE,
Chicago.Census.sf$per.income.gt75E,use="pairwise.complete.obs")## [1] 0.2057667# Make an interactive plot
# http://www.sthda.com/english/wiki/ggplot2-colors-how-to-change-colors-automatically-and-manually
p <- Chicago.Census.sf %>%
ggplot( aes(pop.densityE ,per.income.gt75E, label=NAME)) +
geom_point() +
theme_classic()+
scale_color_gradient(low="blue", high="red")
ggplotly(p)OK our results are dominated by one huge outlier.. census tract 307.02! (mouse over it). Let’s take a look
head(Chicago.Census.sf[Chicago.Census.sf$pop.densityE > 150000,])## Simple feature collection with 1 feature and 43 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 445727.8 ymin: 4647759 xmax: 445775.4 ymax: 4647942
## Projected CRS: NAD83 / UTM zone 16N
## GEOID NAME housevalueE
## 405 17031030702 Census Tract 307.02, Cook County, Illinois 361
## housevalueM totpE totpM tothouseE tothouseM med.incomeE med.incomeM
## 405 69 982 103 708 18 73967 16855
## income.gt75E income.gt75M for.bornE for.bornM house.ageE house.ageM
## 405 289 93 421 96 1974 1
## month.house.costE month.house.costM med.gross.rentE med.gross.rentM
## 405 1232 174 1098 102
## workhomeE workhomeM owneroccupiedE owneroccupiedM totalbedsE totalbedsM
## 405 23 23 361 69 708 18
## broadbandE broadbandM per.income.gt75E per.workhomeE per.owneroccupiedE
## 405 501 68 0.2942974 0.0234216 0.509887
## pop.densityE house.densityE Observed_LocalI IRP_estimate_LocalI Variance_I
## 405 231778.2 167106.9 0.6903913 0.0900584 6.2406
## ZScore_I PValue_Theoretical PValue_MonteCarlo Skew_I Kurtosis_I
## 405 0.2403139 0.8100869 0.708 0.8943683 0.3099905
## LISA_Quadrant LISA_Quadrant_Plot geometry
## 405 High-Low P>0.05 MULTIPOLYGON (((445730.4 46...I then googled this census tract name, which took me here after a bit of detective work. Looks like it is true!

However, I think it would be reasonable to study this census tract separately as a special case, as there are so many people living together. So I shall remove it
# I want to keep everything LESS than 150000
Chicago.Census.sf <- Chicago.Census.sf[Chicago.Census.sf$pop.densityE < 150000,] This gives some improvement, but not much:
cor(Chicago.Census.sf$pop.densityE,
Chicago.Census.sf$per.income.gt75E,use="pairwise.complete.obs")## [1] 0.2911157# Make an interactive plot
# http://www.sthda.com/english/wiki/ggplot2-colors-how-to-change-colors-automatically-and-manually
p <- Chicago.Census.sf %>%
ggplot( aes(pop.densityE ,per.income.gt75E, label=NAME)) +
geom_point() +
theme_classic()+
scale_color_gradient(low="blue", high="red")
ggplotly(p)OK, we can see that there appears to be a positive relationship between the two, but a lot of spread.
Making the model with lm and checking fit
Now let’s make a linear fit using the OLS package. We can see that this has an R2 of 0.497 e.g. the model can only explain ~8% of the variance (spread) seen in the data.
# and using base R
fit1.lm <- lm(per.income.gt75E ~ pop.densityE, data = Chicago.Census.sf,na.action="na.exclude")
fit1.lm##
## Call:
## lm(formula = per.income.gt75E ~ pop.densityE, data = Chicago.Census.sf,
## na.action = "na.exclude")
##
## Coefficients:
## (Intercept) pop.densityE
## 6.508e-02 6.320e-06So from the above, our model is now:
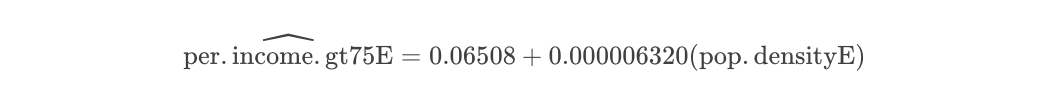
Is our model any good?
Let’s look at the summary:
ols_regress(fit1.lm)## Model Summary
## --------------------------------------------------------------
## R 0.291 RMSE 0.105
## R-Squared 0.085 Coef. Var 94.971
## Adj. R-Squared 0.084 MSE 0.011
## Pred R-Squared 0.079 MAE 0.082
## --------------------------------------------------------------
## RMSE: Root Mean Square Error
## MSE: Mean Square Error
## MAE: Mean Absolute Error
##
## ANOVA
## --------------------------------------------------------------------
## Sum of
## Squares DF Mean Square F Sig.
## --------------------------------------------------------------------
## Regression 0.807 1 0.807 73.891 0.0000
## Residual 8.717 798 0.011
## Total 9.524 799
## --------------------------------------------------------------------
##
## Parameter Estimates
## --------------------------------------------------------------------------------------
## model Beta Std. Error Std. Beta t Sig lower upper
## --------------------------------------------------------------------------------------
## (Intercept) 0.065 0.006 10.161 0.000 0.053 0.078
## pop.densityE 0.000 0.000 0.291 8.596 0.000 0.000 0.000
## --------------------------------------------------------------------------------------#OR summary(fit1.lm)Our model is now: percentage.workfromhome = 0.008+ 0.127xper.income.gt75
We can add a fit using abline (or check out R graph gallery):
plot(Chicago.Census.sf$per.income.gt75E ~ Chicago.Census.sf$pop.densityE,pch=16,cex=.5,col="blue")
abline(fit1.lm)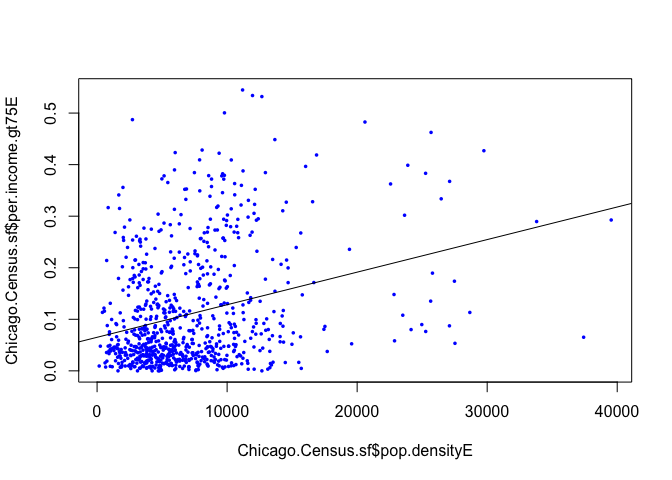
Plotting the results
So we have a model! Let’s look at the results spatially. I’m switching tmap mode to plot to save computer power, just switch it back to view for interactive maps.
tmap_mode("plot")map_actual<- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "per.income.gt75E", style = "quantile",
palette = "-Spectral", border.alpha = 0,
title = "ACTUAL: %ppl making > $75K")+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE)
map_actual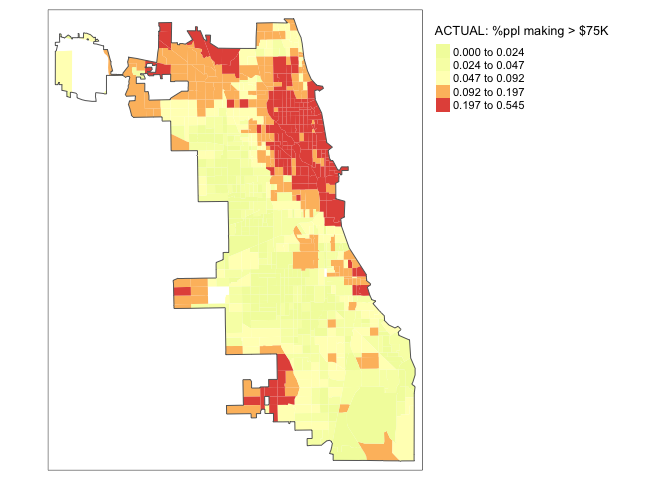
Chicago.Census.sf$Fit1.lm.Prediction <- predict(fit1.lm)
# subset the Illinois census data with the Chicago city limits
maplm1 <- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "Fit1.lm.Prediction", style = "quantile",
palette = "-Spectral", border.alpha = 0,
title = "MODEL1 prediction: %ppl making > $75K")+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE)
maplm1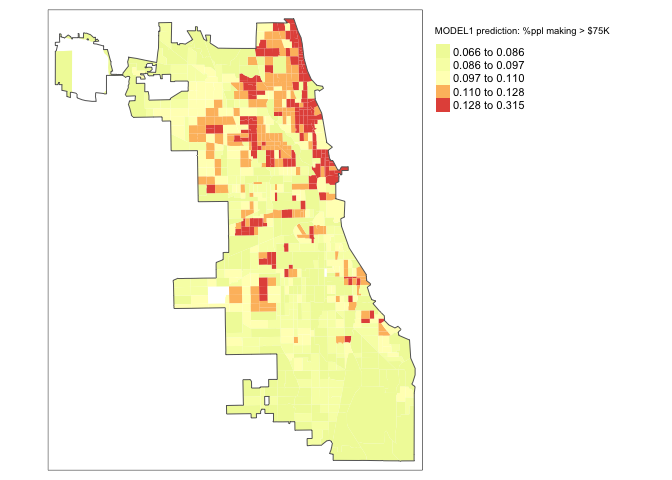
There is some indication of pattern, but it’s not great.
Looking for Spatial autocorrelation in residuals
One of the 4 assumptions around regression is that your data should be independent.
If that is true then our residuals (what is left over) should not have any influence or knowledge of each other. We know that census data is highly geographic, so let’s look at a MAP of the residuals (e.g. the distance from each point to the model line of best fit, high means the model underestimated the data, negative means the model overestimated the data).
To do, this we first add the residuals to our table
Chicago.Census.sf$Fit1.Residuals <- residuals(fit1.lm)Now let’s have a look! If we have fully explained all the data and the data is spatially independent then there should be no pattern.
We can look at the residuals directly.
# subset the Illinois census data with the Chicago city limits
tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "Fit1.Residuals", style = "quantile",
palette = "-RdBu", border.alpha = 0,
title = "Fit 1 residuals.Raw")+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE) 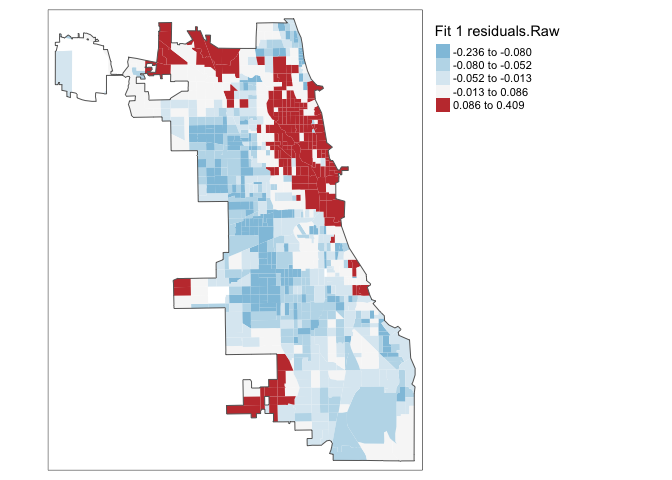
Ouch - but maybe they are not significantly different and we just got unlucky with our colour scale. Let’s look at the extreme residuals by converting to standard deviations.
Chicago.Census.sf$sd_breaks <- scale(Chicago.Census.sf$Fit1.Residuals)[,1]
# because scale is made for matrices, we just need to get the first column using [,1]
my_breaks <- c(-14,-3,-2,-1,1,2,3,14)
tm_shape(Chicago.Census.sf) +
tm_fill("sd_breaks", title = "Fit1 Residuals (StandardDev)", style = "fixed", breaks = my_breaks, palette = "-RdBu") +
tm_borders(alpha = 0.1) +
tm_layout(main.title = "Fit1 Residuals - units = standard deviations from 0", main.title.size = 0.7 ,
legend.position = c("right", "bottom"), legend.title.size = 0.8)+
tm_layout(legend.outside = TRUE) 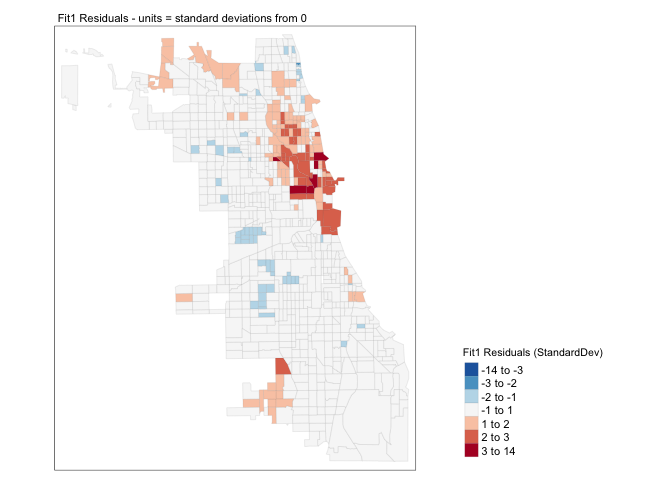
A good model should have very few residuals that are more than 2 standard deviations from zero and no patterns. This doesn’t look good…
To see if we are “seeing pictures in clouds” or there really is a spatial pattern, we can look at a Moran’s scatterplot with a queen’s spatial matrix. The test confirms highly significant autocorrelation. Our p-values and regression model coefficients cannot be trusted.
spatial.matrix.queen <-poly2nb(Chicago.Census.sf, queen=T)
weights.queen <- nb2listw(spatial.matrix.queen, style='B',zero.policy=TRUE)
moran.plot(Chicago.Census.sf$Fit1.Residuals, weights.queen,
xlab = "Model 1 residuals",
ylab = "Neighbors residuals",zero.policy=TRUE)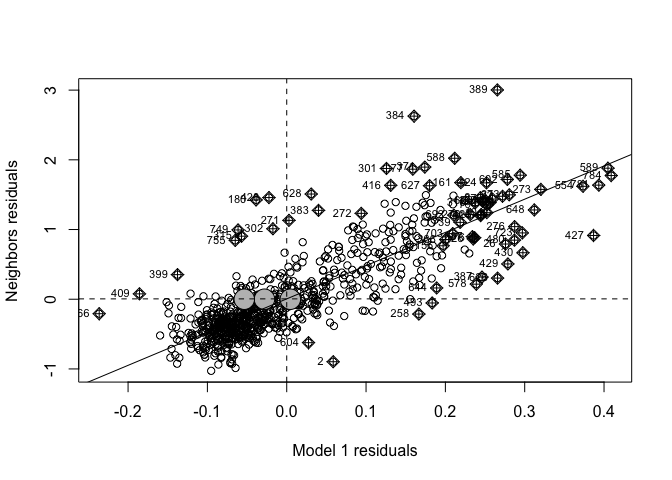
moran.test(Chicago.Census.sf$Fit1.Residuals, weights.queen,zero.policy=TRUE)##
## Moran I test under randomisation
##
## data: Chicago.Census.sf$Fit1.Residuals
## weights: weights.queen n reduced by no-neighbour observations
##
##
## Moran I statistic standard deviate = 37.502, p-value < 2.2e-16
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.7296424283 -0.0012562814 0.0003798373We have a problem! Our residuals definitely do not look like independent random noise - in fact there is a HUGE cluster of high residuals near the centre and other residuals around the edge. They also look highly significant.
The real life interpretation is that in downtown Chicago, the model is underestimating the percentage of people making more than $75K - and in the suburbs it is underestimating.
Let’s try a better model:
Model 2: Multiple regression
Our model isn’t very good. Let’s try multiple predictors - so this is Multiple Linear Regression. I’m going to hope that my spatial dependence can be removed by including some confounding variables.
So, now lets see if adding a second predictor variable makes the fit better. I’m guessing that census tracts where there are more people earning over $75K might also be more likely to own their own home.
# Make an interactive plot
# http://www.sthda.com/english/wiki/ggplot2-colors-how-to-change-colors-automatically-and-manually
p <- Chicago.Census.sf %>%
ggplot( aes(pop.densityE,per.income.gt75E,col= per.owneroccupiedE,label=NAME)) +
geom_point() +
theme_classic()+
scale_color_gradient(low="blue", high="red")
ggplotly(p)There seems to be some relationship. Let’s ADD this to the model and take a look. We now explain a little more..
# using the OLS package
fit2.lm <- lm(per.income.gt75E ~ pop.densityE + per.owneroccupiedE, data = Chicago.Census.sf)We can see the model equation here, it’s harder to see on a scatterplot
fit2.lm##
## Call:
## lm(formula = per.income.gt75E ~ pop.densityE + per.owneroccupiedE,
## data = Chicago.Census.sf)
##
## Coefficients:
## (Intercept) pop.densityE per.owneroccupiedE
## -2.129e-02 8.161e-06 1.896e-01So from the above, our model is now:
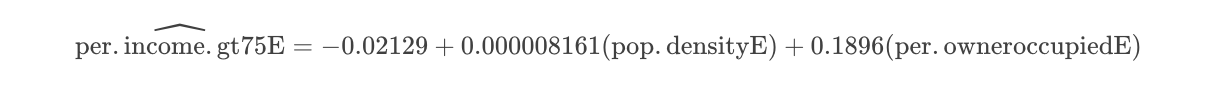
Is model 2 any good?
Look at the summary
ols_regress(fit2.lm)## Model Summary
## --------------------------------------------------------------
## R 0.436 RMSE 0.098
## R-Squared 0.190 Coef. Var 89.376
## Adj. R-Squared 0.188 MSE 0.010
## Pred R-Squared 0.184 MAE 0.075
## --------------------------------------------------------------
## RMSE: Root Mean Square Error
## MSE: Mean Square Error
## MAE: Mean Absolute Error
##
## ANOVA
## --------------------------------------------------------------------
## Sum of
## Squares DF Mean Square F Sig.
## --------------------------------------------------------------------
## Regression 1.814 2 0.907 93.734 0.0000
## Residual 7.711 797 0.010
## Total 9.524 799
## --------------------------------------------------------------------
##
## Parameter Estimates
## -----------------------------------------------------------------------------------------------
## model Beta Std. Error Std. Beta t Sig lower upper
## -----------------------------------------------------------------------------------------------
## (Intercept) -0.021 0.010 -2.048 0.041 -0.042 -0.001
## pop.densityE 0.000 0.000 0.376 11.412 0.000 0.000 0.000
## per.owneroccupiedE 0.190 0.019 0.336 10.200 0.000 0.153 0.226
## -----------------------------------------------------------------------------------------------and examine our prediction
Chicago.Census.sf$Fit2.lm.Prediction <- predict(fit2.lm)
# subset the Illinois census data with the Chicago city limits
maplm2 <- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "Fit2.lm.Prediction", style = "quantile",
palette = "-Spectral", border.alpha = 0,
title = "MODEL2 prediction: %ppl making > $75K")+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE) map_actual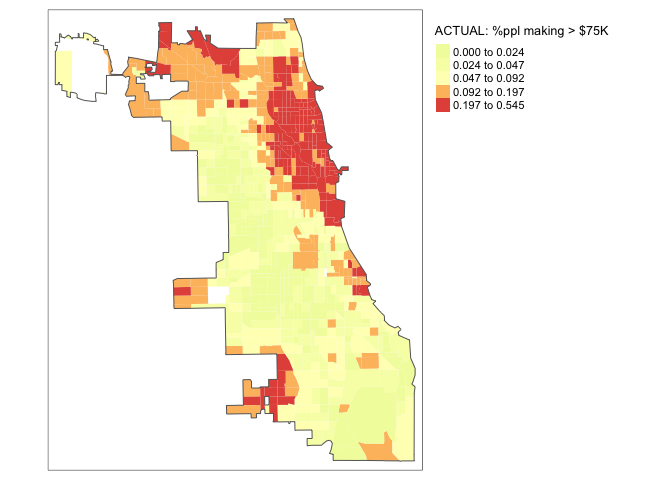
maplm2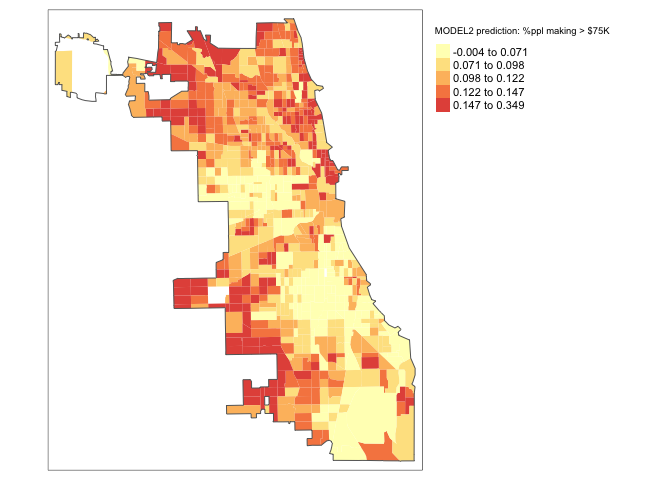
Also, the model improved! A little! We can see that the R2 went up to 0.188. But it’s still pretty rubbish.
Looking for Spatial autocorrelation in Model 2 residuals
How about the spatial autocorrelation?
To do, this we first add the new residuals to our table
Chicago.Census.sf$Fit2.Residuals <- residuals(fit2.lm)Now let’s have a look! If we have fully explained all the data and the data is spatially independent then there should be no pattern.
We can look at the residuals directly:
# subset the Illinois census data with the Chicago city limits
tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "Fit2.Residuals", style = "quantile",
palette = "-RdBu", border.alpha = 0,
title = "Fit 2 residuals: Raw values")+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE) 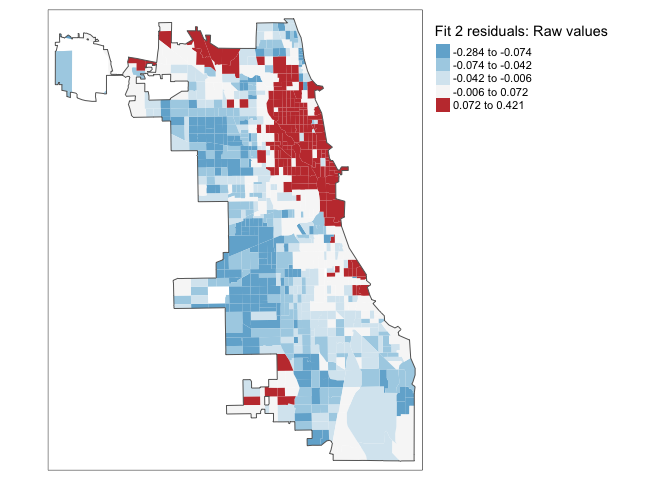
Or.. we can look at the extreme residuals by converting to standard deviation.
Chicago.Census.sf$sd_breaks <- scale(Chicago.Census.sf$Fit2.Residuals)[,1]
# because scale is made for matrices, we just need to get the first column using [,1]
my_breaks <- c(-14,-3,-2,-1,1,2,3,14)
tm_shape(Chicago.Census.sf) +
tm_fill("sd_breaks", title = "Fit2 Residuals (StandardDev)", style = "fixed", breaks = my_breaks, palette = "-RdBu") +
tm_borders(alpha = 0.1) +
tm_layout(main.title = "Fit 2 Residuals (Standard Deviation away from 0)", main.title.size = 0.7 ,
legend.position = c("right", "bottom"), legend.title.size = 0.8)+
tm_layout(legend.outside = TRUE) 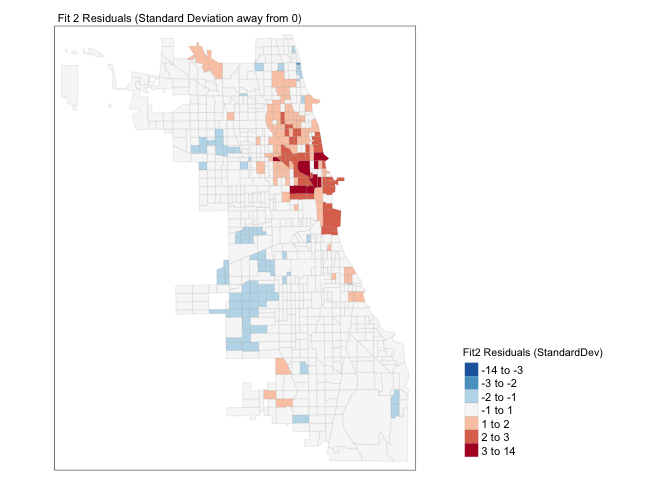
We still have a problem! It is definitely not independent random noise - there are still HUGE clusters of high residuals near the centre and other residuals around the edge. E.g. in downtown Chicago, the model is underestimating the percentage of people making more than $75K - and in the suburbs it is underestimating.
To see if we are “seeing pictures in clouds” or there really is a spatial pattern, we can look at a Moran’s scatterplot with a queen’s spatial matrix. The test confirms highly significant autocorrelation. Our p-values and regression model coefficients cannot be trusted.
spatial.matrix.queen <-poly2nb(Chicago.Census.sf, queen=T)
weights.queen <- nb2listw(spatial.matrix.queen, style='B',zero.policy=TRUE)
moran.plot(Chicago.Census.sf$Fit2.Residuals, weights.queen,
xlab = "Model residuals",
ylab = "Neighbors residuals",zero.policy=TRUE)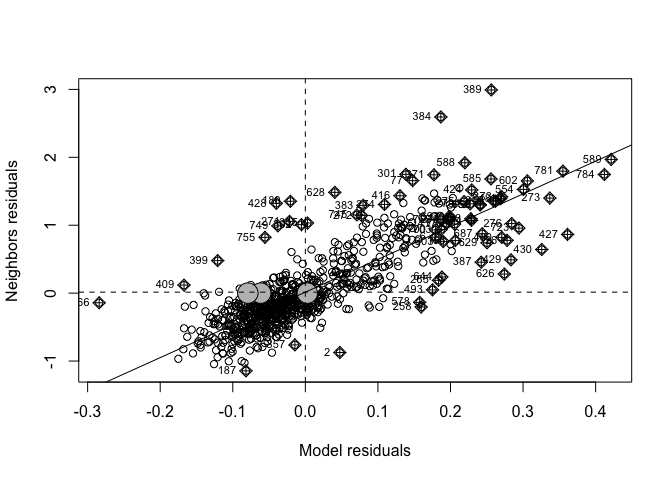
moran.test(Chicago.Census.sf$Fit2.Residuals, weights.queen,zero.policy=TRUE)##
## Moran I test under randomisation
##
## data: Chicago.Census.sf$Fit2.Residuals
## weights: weights.queen n reduced by no-neighbour observations
##
##
## Moran I statistic standard deviate = 37.93, p-value < 2.2e-16
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.7378055887 -0.0012562814 0.0003796571So there is still highly significant spatial autocorrelation.
Comparing models 1 and 2
How do we know if the “improvement” we saw from model 2 is enough to be significant or meaningful?
One way to check is to compare the two models using ANOVA. This conducts a hypothesis test to assess whether there is additional value to adding a new variable.
anova(fit1.lm,fit2.lm)## Analysis of Variance Table
##
## Model 1: per.income.gt75E ~ pop.densityE
## Model 2: per.income.gt75E ~ pop.densityE + per.owneroccupiedE
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 798 8.7172
## 2 797 7.7106 1 1.0065 104.04 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1In this case, the p-value is very low - so it would be very unusual to see this much benefit by chance if per.owneroccupiedE wasn’t useful. E.g, it might be good to keep per.owneroccupiedE.
We can also use AIC a non parametric statistic, where the LOWER number is typically the better fit (taking into account over-fitting). In this case, we can see that it thinks per.owneroccupiedE is a useful variable to keep even if it has limited influence.
AIC(fit1.lm,fit2.lm)## df AIC
## fit1.lm 3 -1339.154
## fit2.lm 4 -1435.307
Model 3: Spatial lag model - OPTIONAL, here for information and your projects
Both models 1 and 2 have not been spatially independent and really should not be used as our final prediction.
If the Moran’s test is significant (as in this case), then we possibly need to think of a more suitable model to represent our data: a spatial regression model. Remember spatial dependence means that (more typically) there will be areas of spatial clustering for the residuals in our regression model. We want a better model that does not display any spatial clustering in the residuals.
There are two general ways of incorporating spatial dependence in a regression model:
- A spatial error model
- A spatial lagged model
The difference between these two models is both technical and conceptual. The spatial error model assumes that the:
“Spatial dependence observed in our data does not reflect a truly spatial process, but merely the geographical clustering of the sources of the behavior of interest. For example, citizens in adjoining neighborhoods may favour the same (political) candidate not because they talk to their neighbors, but because citizens with similar incomes tend to cluster geographically, and income also predicts vote choice. Such spatial dependence can be termed attributional dependence” (Darmofal, 2015: 4)
The spatially lagged model, on the other hand, incorporates spatial dependence explicitly by adding a “spatially lagged” variable y on the right hand side of our regression equation. It assumes that spatial processes THEMSELVES are an important thing to model:
“If behavior is likely to be highly social in nature, and understanding the interactions between interdependent units is critical to understanding the behavior in question. For example, citizens may discuss politics across adjoining neighbors such that an increase in support for a candidate in one neighborhood directly leads to an increase in support for the candidate in adjoining neighborhoods” (Darmofal, 2015: 4)
Mathematically, it makes sense to run both models and see which fits best. We can do this using the lm.LMtests() function. (note, we are skipping over complexity here!). See here for more details on the full process: https://maczokni.github.io/crimemapping_textbook_bookdown/spatial-regression-models.html
But that goes beyond the scope of this course. Here we will try the spatial lag model, because I can imagine that things like broadband access have explicit spatial relationships (e.g. where the cable goes)
To fit a spatial lag model, we use
fit_2_lag <- lagsarlm(per.income.gt75E ~ pop.densityE + per.owneroccupiedE, data = Chicago.Census.sf, weights.queen,zero.policy=TRUE)
fit_2_lag##
## Call:
## lagsarlm(formula = per.income.gt75E ~ pop.densityE + per.owneroccupiedE,
## data = Chicago.Census.sf, listw = weights.queen, zero.policy = TRUE)
## Type: lag
##
## Coefficients:
## rho (Intercept) pop.densityE per.owneroccupiedE
## 0.1125578335 -0.0358066788 0.0000026054 0.1214494029
##
## Log likelihood: 1123.142This is now going beyond the scope of this course, instead of a simple linear model, we are running a generalized additive model (GAM), which is mathematically more complex:
per.income.gt75 = rho(SPATIAL.WEIGHTS*per.income.gt75) + b0 + b1xpop.densityE + b2xper.owneroccupiedE e.g.
per.income.gt75 = 0.11255(SPATIAL.WEIGHTS*per.income.gt75) + -0.0358 + 0.0000026054xpop.densityE + 0.121449xper.owneroccupiedE
You will notice that there is a new term Rho. What is this? This is our spatial lag. It is a variable that measures the percentage working from home in the census tracts SURROUNDING each tract of interest in our spatial weight matrix.
We are simply using this variable as an additional explanatory variable to our model, so that we can appropriately take into account the spatial clustering detected by our Moran’s I test. You will notice that the estimated coefficient for this term is both positive and statistically significant. In other words, when the percentage working from home in surrounding areas increases, so does the percentage working from home in each country, even when we adjust for the other explanatory variables in our model.
Compare model fit
Let’s use AIC to compare all 3 models (ANOVA is inappropriate for a GAM)
AIC(fit1.lm,fit2.lm,fit_2_lag)## df AIC
## fit1.lm 3 -1339.154
## fit2.lm 4 -1435.307
## fit_2_lag 5 -2236.283We see that our new lagged version has the lowest AIC and so is likely to be the best model (so far) for predicting the percentage of people who work from home in each census tract.
Check autocorrelation
Now, if we have fully taken into account the spatial autocorrelation of our data, the spatial residuals should show less pattern and less autocorrelation. Let’s take a look,
# Create the residuals
Chicago.Census.sf$Fit2.LaggedResiduals <- residuals(fit_2_lag)
Chicago.Census.sf$sd_breaks.lagged <- scale(Chicago.Census.sf$Fit2.LaggedResiduals)[,1]
# because scale is made for matrices, we just need to get the first column using [,1]
#plot standard deviations
my_breaks <- c(-14,-3,-2,-1,1,2,3,14)
tm_shape(Chicago.Census.sf) +
tm_fill("sd_breaks", title = "Fit2Lag Residuals (StandardDev)", style = "fixed", breaks = my_breaks, palette = "-RdBu",midpoint=0) +
tm_borders(alpha = 0.1) +
tm_layout(main.title = "Residuals for lagged model (Standard Deviation away from 0)", main.title.size = 0.7 ,
legend.position = c("right", "bottom"), legend.title.size = 0.8)+
tm_layout(legend.outside = TRUE)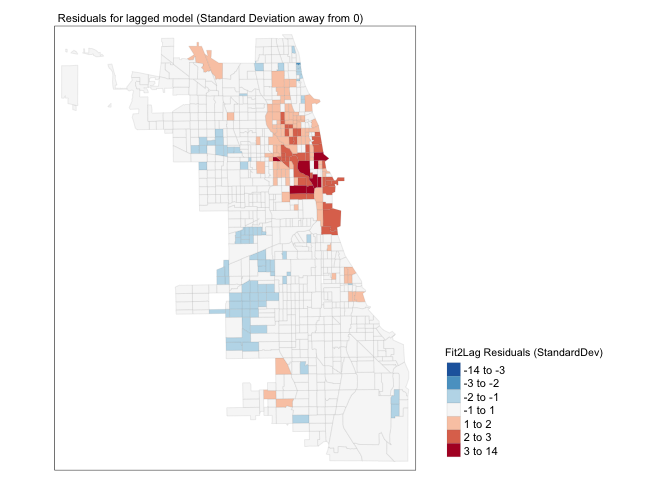
#plot Moran's I
moran.plot(Chicago.Census.sf$Fit2.LaggedResiduals, weights.queen,
xlab = "Model residuals",
ylab = "Neighbors residuals",zero.policy=TRUE)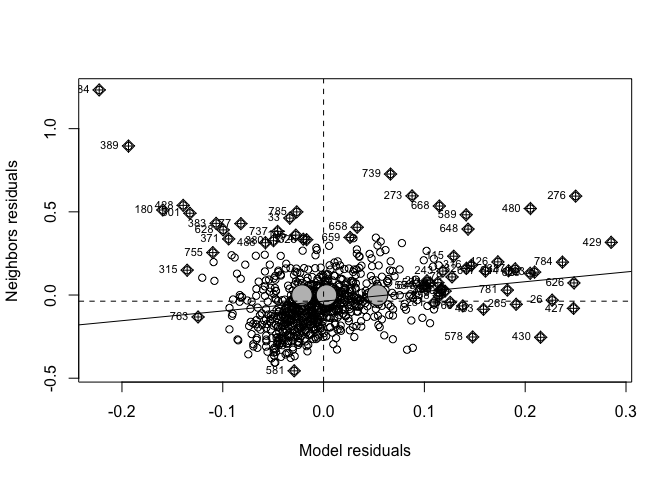
moran.test(Chicago.Census.sf$Fit2.LaggedResiduals, weights.queen,zero.policy=TRUE)##
## Moran I test under randomisation
##
## data: Chicago.Census.sf$Fit2.LaggedResiduals
## weights: weights.queen n reduced by no-neighbour observations
##
##
## Moran I statistic standard deviate = 4.6769, p-value = 1.456e-06
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.0897187219 -0.0012562814 0.0003783798Well… we have improvement, but there is still significant spatial variability left in the model. This suggests that I guessed completely the wrong process for what influences the percentage of people making over $75K in a census tract. In this case, I would go away and think then come back with a new model (amount of green space? proximity to schools or the metro?).
We could also consider adjusting our spatial weights matrix (maybe a “neighbor” is a 2nd order queens, or the census tracks within 50km..).
But even so, we have successfully included location in our model.
Plotting the results
So we have a model!
Finally, we went to all the trouble to create a model predicting the percentage of people who make more than $75K - let’s look at all the results together:
Chicago.Census.sf$Fit2.Lagged.Prediction <- predict(fit_2_lag)
# subset the Illinois census data with the Chicago city limits
maplm2LAG <- tm_shape(Chicago.Census.sf, unit = "mi") +
tm_polygons(col = "Fit2.Lagged.Prediction", style = "quantile",
palette = "-Spectral", border.alpha = 0,
title = "MODEL2LAG prediction: %ppl making > $75K")+
tm_shape(Chicago.city.sf) +
tm_borders()+
tm_layout(legend.outside = TRUE) tmap_arrange(map_actual,maplm1,maplm2,maplm2LAG)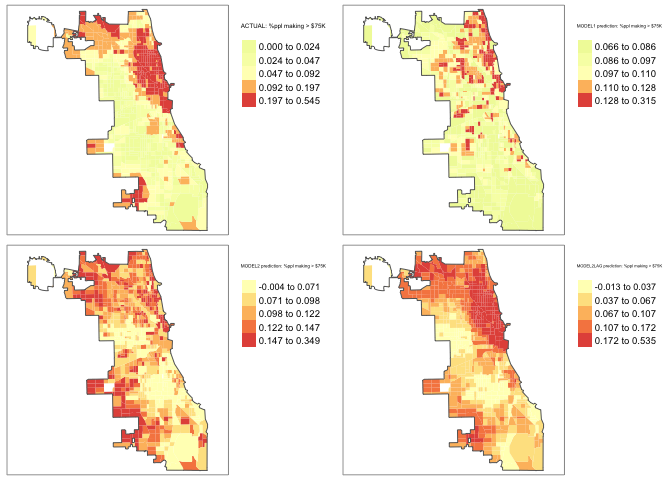
Still not great, but better…. and we could continue to improve given that this model is missing something that pushes down numbers in the suburbs (maybe distance to facilities?).
This process is the centre of an entire course I teach on regression if anyone is interested in the topic: https://online.stat.psu.edu/stat462/
Challenge D2:
- Step 8:
OPTIONAL. Make a new sub-heading called Regression. Below, answer these questions. As in the previous challenges, make sure they are clearly marked to make it easy to find and grade them. NOTE these will be covered in later lectures (see here also: )
- What are the 4 assumptions underpinning linear regression? (https://www.statology.org/linear-regression-assumptions/)
- If the data is spatially auto-correlated, which assumption is broken?
- What is the ecological fallacy and why is it important when looking at census data
- If I tested 3 models using AIC and saw the values (Model1: -2403, Model2: -2746, Model3:-3102), which model would I be likely to choose?
- Step 9:
Now for your city. Conduct a SIMPLE LINEAR REGRESSION analysis to assess whether the percentage of people who work from home is linked to the percentage of people who have access to broadband.
Make sure to tell me what you are doing at each stage and to interpret your output in text. Note, we will also be going through this in lectures.
- Step 10:
Now for your city. Conduct a MULTIPLE LINEAR REGRESSION analysis to assess whether the percentage of people who work from home is linked to the percentage of people who have access to broadband AND some other variable you think might influence it.
Make sure to tell me what you are doing at each stage and to interpret your output in text.
- Step 11:
Compare models 1 and 2 using the techniques in the tutorial
- Step 12:
The American Community Survey data was collected in 2017. Do you think these results are stable now? If not, why not?
- Step 13:
OPTIONAL.
For 4 show me something new points, go further. Apply and interpret either/or/both multiple regression (e.g. two or more things that might influence the percentage of people who work from home), AND/OR apply and interpret a spatial lag model. I will also consider exceptional analyses for course credit.
E. Above and beyond
Remember that an A is 93%, so you can ignore this section and still easily get an A. But here is your time to shine. Also, if you are struggling in another part of the lab, you can use this to gain back points.
To get the final 4 marks in the lab, you need to show me something new, e.g. you need to go above and beyond the lab questions in some way.
- You get 2/4 for doing something new in any way
- You get 4/4 for something really impressive (see the two ideas in the steps)
Please tell us in your R script what you did!
F. Submitting your Lab
Remember to save your work throughout and to spell check your writing (left of the knit button). Now, press the knit button again. If you have not made any mistakes in the code then R should create a html file in your lab 6 folder which includes your answers. If you look at your lab 6 folder, you should see this there - complete with a very recent time-stamp.
In that folder, double click on the html file. This will open it in your browser. CHECK THAT THIS IS WHAT YOU WANT TO SUBMIT
Now go to Canvas and submit BOTH your html and your .Rmd file in Lab 6.
Lab 6 submission check-list
For all answers: Full marks = everything down at a high standard, in full sentences as appropriate with no parts of your answer missing. Imagine it as an example I use in class
HTML FILE SUBMISSION - 5 marks
RMD CODE SUBMISSION - 5 marks
MARKDOWN STYLE - 10 MARKS
We will start by awarding full marks and dock marks for mistakes.LOOK AT YOUR HTML FILE IN YOUR WEB-BROWSER BEFORE YOU SUBMIT
TO GET 13/13 : All the below PLUS your equations use the equation format & you use subscripts/superscript as appropriate
TO GET 12/13 - all the below:
- Your document is neat and easy to read.
- Answers are easy to find and paragraphs are clear (e.g. you left spaces between lines)
- You have written in full sentences, it is clear what your answers are referring to.
- You have used the spell check.
- You have used YAML code to make your work look professional (themes, tables of contents etc)
Above and beyond: 4 MARKS
- You get 2/4 for doing something new in any way
- You get 4/4 for something really impressive
An easy example, try conducting a Moran’s analysis for your census data. Bonus marks if you can convert a column to TRUE/FALSE and do a join counts analysis on it! [100 marks total]
Overall, here is what your lab should correspond to:
| Grade | % Mark | Rubric |
|---|---|---|
| A* | 98-100 | Exceptional. Not only was it near perfect, but the graders learned something. THIS IS HARD TO GET. |
| NA | 96+ | You went above and beyond |
| A | 93+: | Everything asked for with high quality. Class example |
| A- | 90+ | The odd minor mistake, All code done but not written up in full sentences etc. A little less care |
| B+ | 87+ | More minor mistakes. Things like missing units, getting the odd question wrong, no workings shown |
| B | 83+ | Solid work but the odd larger mistake or missing answer. Completely misinterpreted something, that type of thing |
| B- | 80+ | Starting to miss entire/questions sections, or multiple larger mistakes. Still a solid attempt. |
| C+ | 77+ | You made a good effort and did some things well, but there were a lot of problems. (e.g. you wrote up the text well, but messed up the code) |
| C | 70+ | It’s clear you tried and learned something. Just attending labs will get you this much as we can help you get to this stage |
| D | 60+ | You attempt the lab and submit something. Not clear you put in much effort or you had real issues |
| F | 0+ | Didn’t submit, or incredibly limited attempt. |
Website created and maintained by Helen Greatrex. Website template by Noli Brazil