Lab 2: Playing with data
GEOG-364 - Spatial Analysis
Welcome to Lab 2!
The aim of this lab is to start looking at tables of data and to apply z-scores and t-tests on frost days in the USA.
We will also be creating a lab script template that makes life easier in the future. As before, much of this is based on tutorials that I will point you to as we go through. By the end of this lab you will be able to:
- Make a markdown template
- Read in data from an excel file
- Conduct exploratory data analysis
- Wrangle a table of data
- Make initial plots and maps
Assignment 2 is due by midnight the night before your next lab on Canvas. Your job is to submit the requirements on this page.
See this page or go to canvas for assignment guidelines.
Need help? Add a screenshot/question to the discussion board here: LAB 2 DISCUSSION BOARD
Step A: Make a lab script template
Setting up your markdown files takes time and can get repetitive. Making a template skips a lot of future set up.
To to this, we are going to follow these steps:
- A1 Set up the lab
- A2 Understand and edit YAML code
- A3 Load libraries
- A4 Edit code chunk options to remove library output from your html files
- A5 Save your lab script template
A1. Set up the lab
First, we want to set up R in the same way as Lab 1, creating a project file and a blank markdown document.
-
Open R-Studio.
Create a new R-Project in your GEOG-364 folder calledGEOG364_Lab2_PROJECT.
Reminder: Tutorial 2C: Projects.
-
Go on Canvas to the Lab 2 page and download the two datasets (frostdata.xlsx and NewYork.xslx).
Put them in yourGEOG364_Lab2_PROJECTfolder.
-
We forgot to install some packages!
Go to to the packages tab, click install and download/install thereadxl,usmap,viridisand theggstatsplotpackages.
Reminder: Tutorial 2B: Packages and/or Tutorial 3G: Packages cheatsheet.
-
Create a new RMarkdown file titled
GEOG-364 Lab 2and set the author name to your USER-ID e.g. hlg5155
We are doing this so that we can grade more anonymously.
Reminder: Tutorial 4B: Create a Markdown Doc.
-
Delete all the text below line 11.
Press knit and save asGEOG364_Lab2_userID_CODE.Rmde.g. for meGEOG364_Lab2_hlg5155_CODE.Rmd
Your R-Studio screen should look something like this. IF NOT, STOP AND TALK TO A TEACHER.
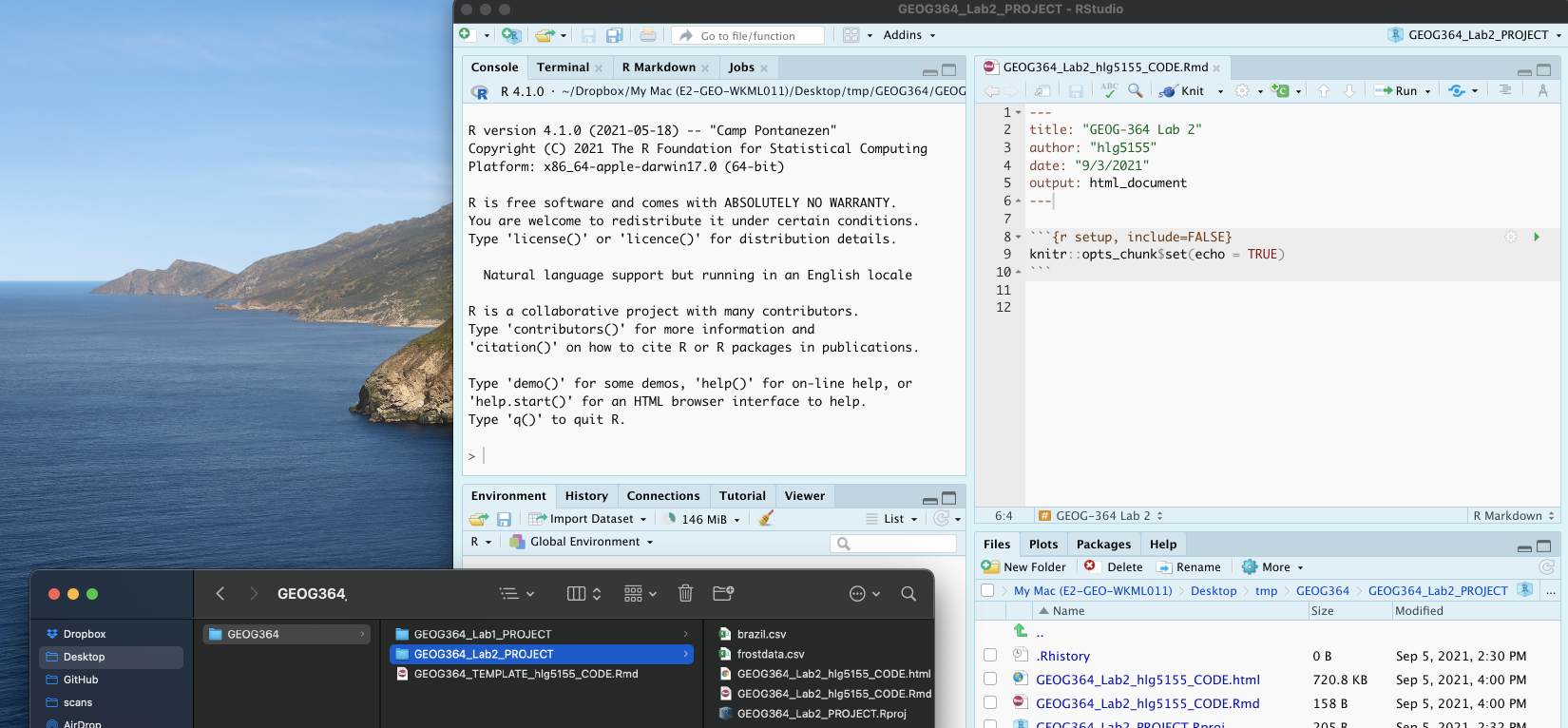
A2. Understand and edit your YAML code
Our output still looks pretty boring when we knit. Work through Markdown Tutorial 4C, D and E to understand and edit your YAML code.
Use the tutorial to change your YAML code to match the text in the tutorial. Your code should now include at a minimum
- A floating table of contents (will appear as you add headings)
- Auto-numbering sections
- A theme of your choice that’s not lumen
A3: Load libraries
We downloaded & installed many libraries last week. As discussed, even though they are downloaded, we need to load them EVERY TIME we want to use them (in the way you click on an app on your phone before you can use it).
It’s best to do this at the the start of each script, so let’s do this now.
-
Click on your lab script (the Rmd file) after line 11.
Press enter a few times and make a new level-1 heading called# Load Libraries.
Reminder on headings: Tutorial 2G.
Press enter a few times, then make a new code chunk containing this code.
library(tidyverse) library(sp) library(sf) library(readxl) library(skimr) library(tmap) library(USAboundaries) library(viridis)
-
Press the green arrow on the right of the code chunk to run the code inside it.
You will see a load of “welcome text” telling your details about the packages you just loaded.
Press the green arrow AGAIN. The text should disappear unless there is an error.
YOU NEED TO RE-RUN THIS CODE CHUNK EVERY TIME YOU OPEN R.
A4: Edit code chunk options
Press knit. You should see that all the “welcome text” has come back, making your report look unprofessional.
Let’s remove this by editing our code chunk options.
- Follow Tutorial 4F to edit your global code chunk options to remove messages and warnings.
A5: Save your lab script template
Your lab script should now look like this, but with your theme and YAML options of choice (you might have a few different libraries than in my screenshot). You should also be able to knit it successfully. If not, go back and do the previous sections!
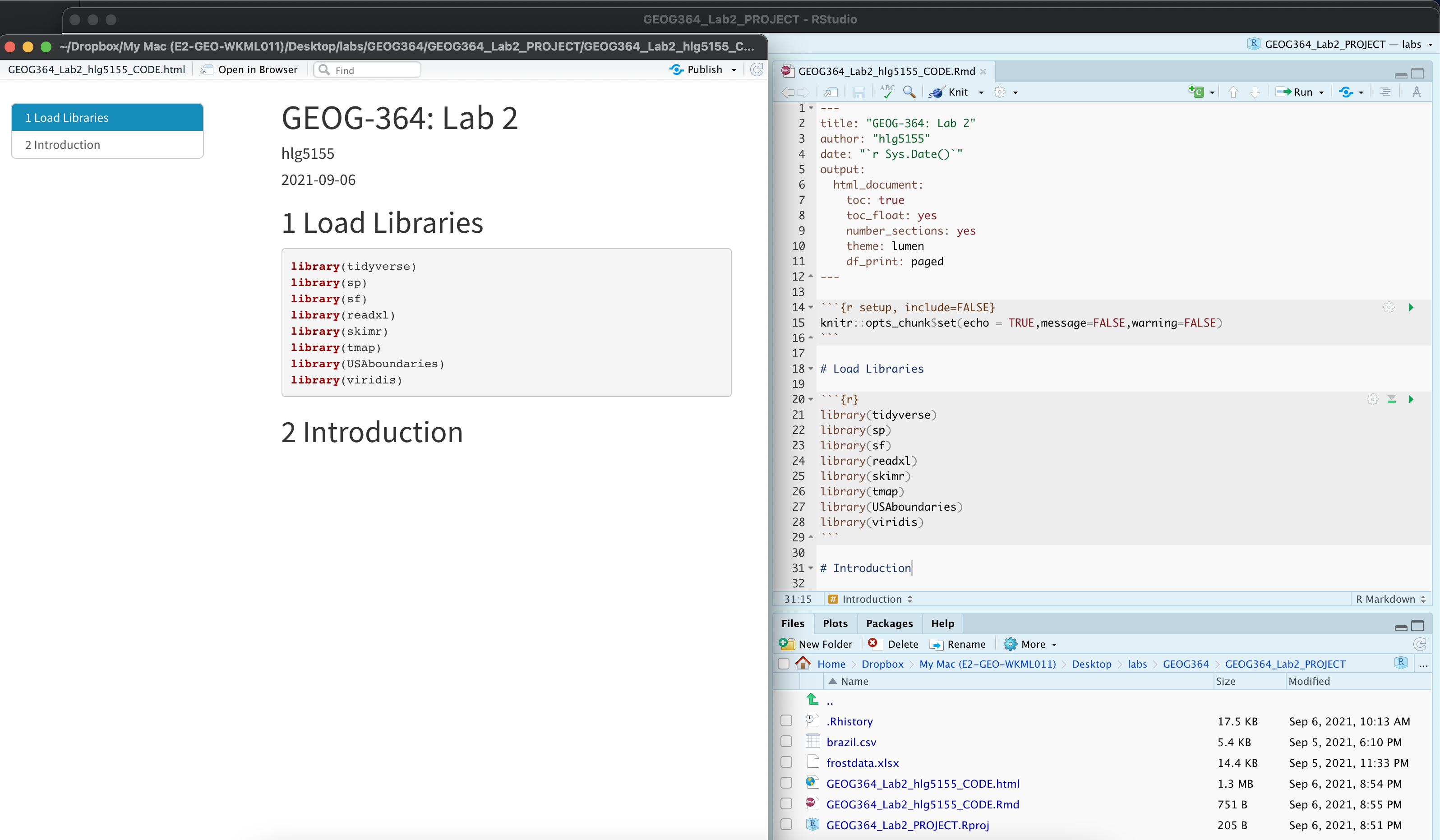
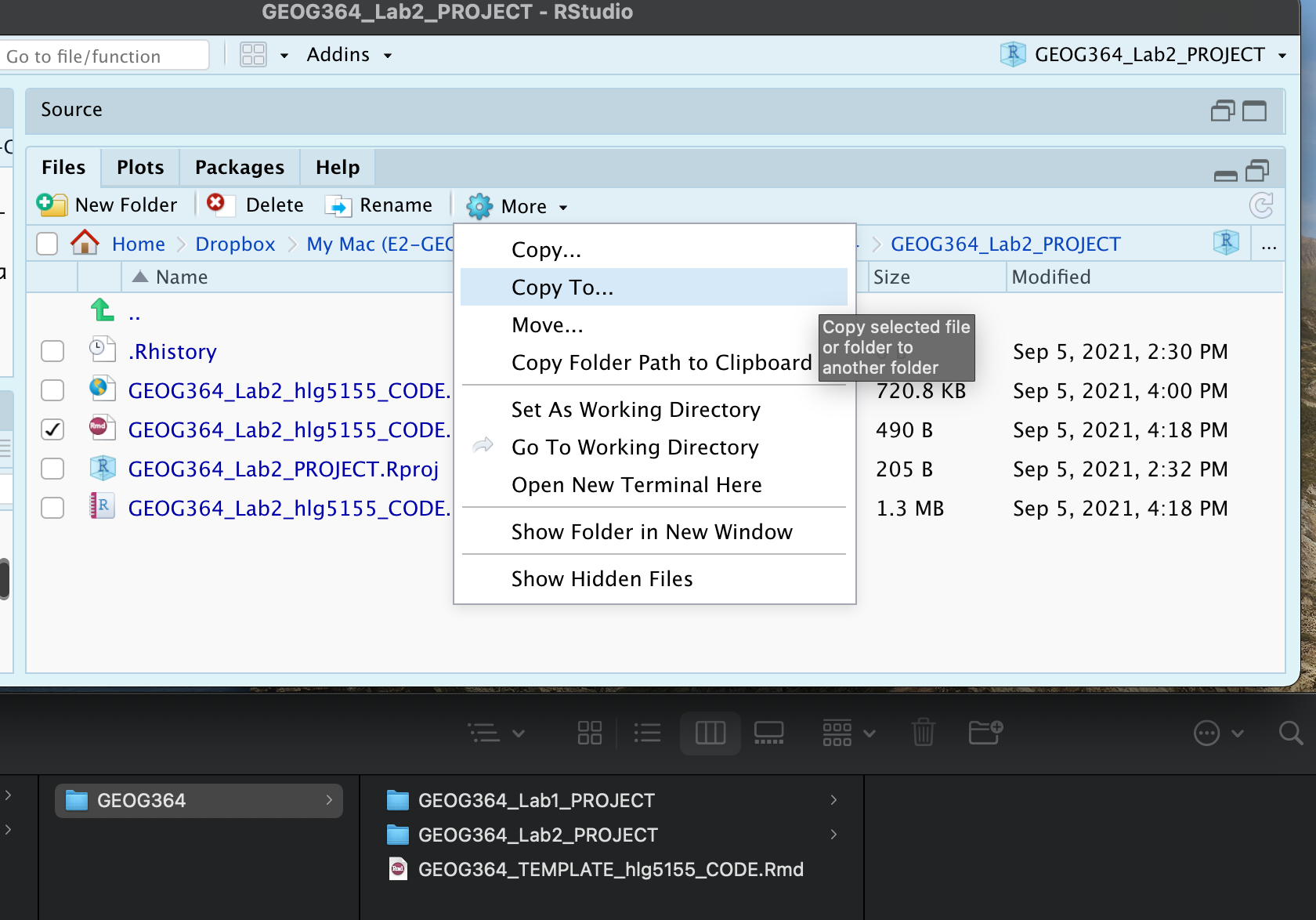
You can use steps A1-A5 for every new lab to set up your lab script. But it is much easier to save the file we have just created as a template, then in future labs we can just make a copy. To do this quickly:
-
Go to the files tab (R should be “looking” in your Lab 2 folder).
- Check the box by
GEOG364_Lab2_userID_CODE.Rmd(with your ID) - Now click on the More menu, then “Copy To”.
- Make a copy in your main GEOG-364 folder called
GEOG364_TEMPLATE_userID_CODE.Rmd. - If you’re on R-Studio-Cloud, just make a copy in the same folder.
Step B: Last Frost Date Analysis
Now, the lab! This section is based on data from Chapter 6 of the textbook. Specifically we are going to conduct some exploratory data analysis on average last spring frost dates across the South East USA.
To to this, we are going to follow these steps:
- B1 Investigate the topic before touching the data
- B2 Read the excel file containing the data into R
- B3 Calculate summary statistics and “wrangle” the data
- B4 Calculate the z-score for each location
- B5 Make some intial plots
- B6 Make some intial maps
- B7 Calculate a t-test
B1: Exploratory Investigations
Before we touch any data, it’s important to start with words. We need to summarise what we already know about the dataset, the population under study and any important context.
The aim of this lab is to analyse the “average last frost dates” obtained from weather stations across the South Eastern USA. E.g. what day of year, on average, is the final day to get frost. See chapter 6 of the textbook for a brief summary.
The textbook (and us) are using data obtained from this dissertation to assess the spatial distribution of average spring frost dates: Parnell, 2005, “A Climatology of Frost Extremes Across the Southeast United States, 1950–2009”:
https://www.proquest.com/openview/d5a7301f0cbe941ead48c96888f791b8/1?pq-origsite=gscholar&cbl=18750&diss=y
-
Choose any state out of Alabama, Florida, Georgia, North Carolina, South Carolina or Virginia.
Choose a different state to your friends
- Read the abstract of the study above to understand the dataset (click the link and skim read pages iv and v, e.g. the bit before the table of contents).
-
In your script, press enter a few times, then make a new level-1 heading called
Last Spring Frostand press enter a few times.I’m going to stop saying, “press enter a few times”, or “add a blank line” now. Keep doing it!
-
In the text below, briefly summarise the topic and data (imagine you are asked to summarise in class)
For example you could summarise:- What topic/question are we studying?
- What is the context? Why was the original study conducted?
- Specifically, what data are we using? What is the unit of observation?
- What are the constraints/boundaries of the data (e.g. it’s an average across which years? Over what time-period?)
- Anything else that might be relevant to someone analysing the data
- Given the topic, are there any confounding variables, or things we should be thinking about. E.g. why might I be concerned about climate change looking at a single average last frost?
Note,there is a spell check next to the knit button at the top of the script and press knit regularly to check it all looks good
B2: Read in the frostdata excel file
Go to your lab 2 folder. Double click frostdata.xslx to open it in excel and take a look at the data.
We now want to load this into R.
You should see a spreadsheet/table/data.frame with these columns:
- Station: The name of the weather station
- State: The US State that the station resides in
- Type_Fake: A synthetic column I added to put in a “type” of station
- Latitude: The latitude of the station (degrees)
- Longitude: The longitude of the station (degrees)
- Elevation: The elevation of the station (feet)
- Dist_to_Coast: The distance from the station to the coast (miles)
- Avg_DOY_SpringFrost: The Day-Of-Year of the average final spring frost date for that station
When I say Day-Of-Year, I mean a number from 1-365 representing the month/day of the year e.g. Jan-1:1, Jan-2:2… Jan-31:31, Feb-1:32… Dec-31:365. We use this number instead of the month/day because its easier to analyse.
-
Use Tutorial 6A to read the data into R and save as a variable called
frost.
-
Take a look at the data. To view the data as a spreadsheet like you did in excel:
- Either, go to the environment quadrant and click on its NAME (e.g. click the word frost not the blue arrow)
- Or.. use the command
View(frost).
B3. Summary Statistics
Make a new level-2 heading called Summary Statistics e.g ## Summary Statisics
B3.1 General summaries
Create a new code chunk. Apply the
glimpse()command to the frost variableCreate a new code chunk. Apply the
skim()command to the frost variableIn the text below the code chunk, use your knowledge from your reading, this lab script and the skim command output, to summarise the dataset for someone who has never seen it before (e.g. FULL SENTENCES), including:
- A specification of the unit-of-observation under study (as specific as possible). E.g. what does each row represent
- What attributes/information we know about each unit? E.g. what columns do we have
- A description of each column & units as a bullet point/numbered list
Help here: https://www.markdownguide.org/basic-syntax/ - The number of units in our sample (e.g. the number of rows)
- The mean longitude
- The standard deviation of the distance to the coast
- Your chosen State.
B3.2 Specific columns
Sometimes we want to deal with only one specific column in our spreadsheet/dataframe, for example applying the mean, standard deviation, inter-quartile range command to say just the distance_to_the_coast.
To do this, we use the $ symbol. For example, here I’m simply selecting the data in the elevation column only and saving it to a new variable called elevationdata.
elevationdata <- frost$ElevationTry it yourself. You should have seen that as you typed the $, it gave you all the available column names to choose from.
This means we can now easily summarise specific columns. For example:
summary(frost)will create a summary of the whole spreadsheet,summary(frost$Longitude)will only summarise the Longitude column.
mean(frost$Dist_to_Coast)will take the mean of the Dist_to_Coast column in the frost dataframe.
-
Press enter a few times and make a new code chunk. Inside, calculate:
- The mean of the Longitude column in the frost dataframe
- The minimum distance to the coast using the
mincommand.
E.g. apply themincommand to theDist_to_Coastcolumn of the frost dataframe - The median climatological frost date.
E.g. apply themediancommand to theAvg_DOY_SpringFrostcolumn of the frost dataframe (bonus - explain what the median is) - The interquartile range of the Latitude of the frost data (hint, google the command)
B3.2 Summaries by group
Make a new level 2 sub-heading called Group statistics.
The table command
Sometimes we want to count the occurrences of some category in our dataset. For example, if you look at the frost dataset, it might be interesting to know how many stations were in each US State. To do this, we use the table command: We can use the table command to assess how many rows of our data.frame/spreadsheet fall into different groups. See Tutorial 7B for how to use it and some online tutorials.
-
Use the table command on the State column of the frost dataframe.
In the text below the code chunk, in full sentences, tell me how many stations are in the US-State you chose in Step 14.
-
Now create a two-way table of the
Statecolumn vs theType_Fakecolumn.
In the text below the code chunk, in full sentences, tell me how many agricultural stations are in your chosen tate.
Statistics by group
What if we want to do more than just count the number of rows? Well, we can use the group_by() and summarise() commands and save the answer to a new variable.
See Tutorial 7C for a worked example.
-
Copy/tweak the code in tutorial 7c to:
- split the frost dataframe by the
Statecolumn, - Calculate the maximum, minimum and mean average spring final frost day (
Avg_DOY_SpringFrost) - save the result as a new variable called
frost.summary.state. - print the results
- Using your output, write under the code chunk in a full sentence what the mean spring final frost Day of Year is for your chosen state.
- split the frost dataframe by the
B3.3 Histograms
Sometimes it’s just nice to visualise a distribution, using a histogram. You can see tiny mini ones for each variable/column in the output of the skim command, but let’s make something more professional.
- Using Tutorial 10A, create a histogram of the Elevation column in the frost dataset. be as creative/professional as possible.
B3.4 Testing Normality
For many applications, we also want to assess whether our data has a specific distribution or not (for example, normal, exponential..). We can do this using a plot called a QQ-plot (quantile-quantile plot) and statistical tests such as the Wilks-Shapiro test for normality.
This is covered in Tutorial 9A
- Using a QQ-Norm plot and referring back to your histogram, describe the distribution and assess the normality of the the Elevation column of the frost data.
B4 Creating z-scores
Make a new level-2 heading called Z-Score mapping
In the lecture, we talked about finding z-scores (e.g. how unusual a value is AKA how many standard deviations away from the mean). Let’s calculate a new column in our dataset with the z-score of the last spring frost date.
Create a new code chunk and copy/run this code.
mean.frost <- mean(frost$Avg_DOY_SpringFrost) sd.frost <- sd(frost$Avg_DOY_SpringFrost) frost$ZScore <- (frost$Avg_DOY_SpringFrost - mean.frost) / sd.frost
Hopefully you can see that we’re just applying the Z-score equation to each row of the Avg_DOY_SpringFrost column of the frost dataset:
Have a look at the frost table itself (e.g. click on its name in the environment tab), or look at the summary. you should see the new column. Essentially the ZScore column now contains a normalised value of how unusually early or late that location is.
B5 Spatial mapping
Make a new level 2 sub-heading called Mapping.
So far, we have ignored the fact our data has a location! We will cover this in more detail in lab 3, but for now, let’s make a quick map. To do this, we need to make R realise that our data contains spatial coordinates.
Create a new code chunk and add this code:
Create a code chunk and copy/run this code. WE will discuss this in detail next week.
frost.sf <- st_as_sf(frost,coords = c("Longitude", "Latitude"),crs=4326)
The QTM command allows us to make quick interactive plots.
Create a code chunk and copy/run this code. It should make an interactive map of the Elevation column. Tweak the code to map your z-scores AKA recreate the map in Chapter 6 of the textbook.
tmap_mode("view") qtm(frost.sf,dots.col="Elevation")
-
You can now make QTM maps for any variable/column in the dataset e.g.
qtm(frost.sf,dots.col="Elevation")for the elevation column.
Play with the different variables, explore the data and reflect on what you have learned in the Exploratory Data Analysis. (Hint, the textbook chapter 6 might help)
For example, you could include thoughts/plots/maps/statistics on questions such as:- What is the pattern of the last spring frost dates and what influences it?
- Was it appropriate to apply the Z-score in this case? (prove it!)
- Is the last frost day a raster or a vector dataset? Are there consequences of using a point dataset to measure it?
Step C New York Data Analysis
Now it’s your turn!
The other file in your Lab 2 folder should be called NewYork.xlsx. It contains real airbnb price data across New York City for 2021 from this source (http://insideairbnb.com/get-the-data.html - I did some quality control)
Use what you have learned to read the data into R, explore it and tell me what you find.
DO NOT SPEND ALL DAY ON THIS!
Set a timer for 45mins, turn off the internet and see how far you get. That is enough (if you do more, that’s fine, but about 45mins work (MAX) is all I expect here)
Hint, follow the same steps. AKA
- Create a heading then describe the dataset in words in a few sentences
- Use headings/sub-headings etc to keep your analysis tidy. Knit often!
- Create a new heading called Data input
- Read in the data and assign it to a variable like
NewYork - Create a new heading called Exploratory Data Analysis and see what you find e.g.
- Describe the dataset itself e.g. what variables are there, what’s the unit of observation, how much data is there
- Do some summary statistics, tables, plots and maps
- See what interesting stories you find. For example, you could look at the rental type in each district, make maps, plot prices, summarise prices by district/location/type/bedrooms, see if one area is unusually high/low and google to find out why….
This is brand new data that I have not looked at myself. There will be many interesting stories in it, so try to find your own path through the data (e.g. try to take a different route to anyone you work with closely)
Good luck!
Step D. Submitting your Lab
Remember to save your work throughout and to spell check your writing (left of the knit button). Now, press the knit button again. If you have not made any mistakes in the code then R should create a html file in your lab 2 folder which includes your answers. If you look at your lab 2 folder, you should see this there - complete with a very recent time-stamp.
In that folder, double click on the html file. This will open it in your browser. CHECK THAT THIS IS WHAT YOU WANT TO SUBMIT
Now go to Canvas and submit BOTH your html and your .Rmd file in Lab 2.
Lab 2 submission check-list
You lose points on a sliding scale as things don’t work out or are missed
HTML FILE SUBMISSION - 7 marks
RMD CODE SUBMISSION - 7 marks
MARKDOWN/CODE STYLE - 16 MARKS
- Your code and document is neat and easy to read. LOOK AT YOUR HTML FILE IN YOUR WEB-BROWSER BEFORE YOU SUBMIT.You have written in full sentences, it is clear what your answers are referring to.*
MARKDOWN LEVEL-UP: YOU MADE YOUR YAML WORK: 10 MARKS
- Your markdown file knits correctly and includes a new theme, a floating table of contents and autonumbered sections. Your libraries do not print out the “welcome text”*
FROST DATE: ALL THE WORDS: 10 MARKS
- Full marks for thoughtful answers to all the questions written in a way that tells the reader all they need to know about the study. For example
- Full marks would say that the unit of observation is weather stations sampled where the mean frost date in Feb/March in the USA, talking about the 1950:1999 average, mentioning why climate might be a confounding factor.
- ~7 or 8/10 You clearly tried hard to answer everything but maybe missed some nuance. You said the unit of observation was the weather station etc.
- 6/10: You tried hard & used full sentences but several things missing or factually incorrect
- 4 or 5/10 You wrote anything.
- Full marks would say that the unit of observation is weather stations sampled where the mean frost date in Feb/March in the USA, talking about the 1950:1999 average, mentioning why climate might be a confounding factor.
FROST DATE: SUMMARY STATISTICS: 10 MARKS
- You have clearly done the summary statistics and answered the questions in a way that’s easy for us to find as graders.*
FROST DATE: TABLES & SUMMARYS BY GROUP: 10 MARKS
- You managed to create your tables and summaries by group and answered all associated questions (1 way table, 2 way table and summary by group), so lose a few marks for each missing.*
FROST DATE: PLOTS: 10 MARKS
- The histograms and spatial maps are all there and look good. You also thoughtfully answered all the questions asked in these sections.
NEW YORK: EXPLORATION: 20 MARKS
- This is all your “show me something new!”
- 5/20 - Marks for attempting anything
- 10/20 - You read in the data and did the basic summaries, maybe a basic plot
- 14/20 - You managed to make professional looking plots or maps and you have text describing things you have found.
- 18/20 - More sophisticated work, especially interpreting output. You thoughtfully chose your analysis rather than just randomly making plots
- 20/20 - Wow, we just learned stuff - you could share this with the AirBnb folks (THIS IS HARD TO ACHIEVE)
[100 marks total]
Overall, here is what your lab should correspond to:
| Grade | % Mark | Rubric |
|---|---|---|
| A* | 98-100 | Exceptional. Not only was it near perfect, but the graders learned something. THIS IS HARD TO GET. |
| NA | 96+ | You went above and beyond |
| A | 93+: | Everything asked for with high quality. Class example |
| A- | 90+ | The odd minor mistake, All code done but not written up in full sentences etc. A little less care |
| B+ | 87+ | More minor mistakes. Things like missing units, getting the odd question wrong, no workings shown |
| B | 83+ | Solid work but the odd larger mistake or missing answer. Completely misinterpreted something, that type of thing |
| B- | 80+ | Starting to miss entire/questions sections, or multiple larger mistakes. Still a solid attempt. |
| C+ | 77+ | You made a good effort and did some things well, but there were a lot of problems. (e.g. you wrote up the text well, but messed up the code) |
| C | 70+ | It’s clear you tried and learned something. Just attending labs will get you this much as we can help you get to this stage |
| D | 60+ | You attempt the lab and submit something. Not clear you put in much effort or you had real issues |
| F | 0+ | Didn’t submit, or incredibly limited attempt. |
Website created and maintained by Helen Greatrex. Website template by Noli Brazil