Lab 6: Autocorrelation
GEOG-364 - Spatial Analysis
Welcome to Lab 6!
The aim of this lab is to continue work on autocorrelation, especially Moran’s I. By the end of the lab you will be able to:
- Load data from a variety of sources, including the US census
- Conduct join counts and Moran’s I analyses on real data
- Consider environmental vulnerability
Assignment 6 is due by midnight the night before your next lab on Canvas. Your job is to submit the requirements on this page.
See your canvas assignment here.
Need help? Add a screenshot/question to the discussion board here: LAB 6 DISCUSSION BOARD
A: Set up the lab
A1: Sign up for Census API (if you didn’t last week)
IF YOU DIDN’T LAST WEEK: You can easily access US census data within R, but you need to sign up in advance for a password.
https://api.census.gov/data/key_signup.html
You can use Penn State as the organisation. This is just you promising that you will follow the terms and conditions when using this data. In a few minutes, e-mail you a personal access code. Click the link in the e-mail to activate.
A2: Create your lab project
Follow the instructions in Labs 1-4 to create your project file and a blank markdown document. e.g.
Open R-Studio. Create a new R-Project in your GEOG-364 folder called
GEOG364_Lab6_PROJECT.Make a copy of the lab template Rmd file and move it into your project folder.
DOUBLE CLICK ON THE GEOG364_Lab6_PROJECT.RPROJ FILE IN YOUR PROJECT FOLDER TO OPEN R.
Click on your lab 6 .Rmd file in the files tab to open the script
(You should not have to search if you are in your Lab 6 project):- Change the title to Lab 6.
- Change the theme if you like or add in any other features
- Remember you can edit your lab in the “editor” mode by clicking on the A at the top right
- Change the title to Lab 6.
IF YOU ARE ON R-STUDIO CLOUD, Re-install the packages by copying the commands here into the CONSOLE: Tutorial 2:.
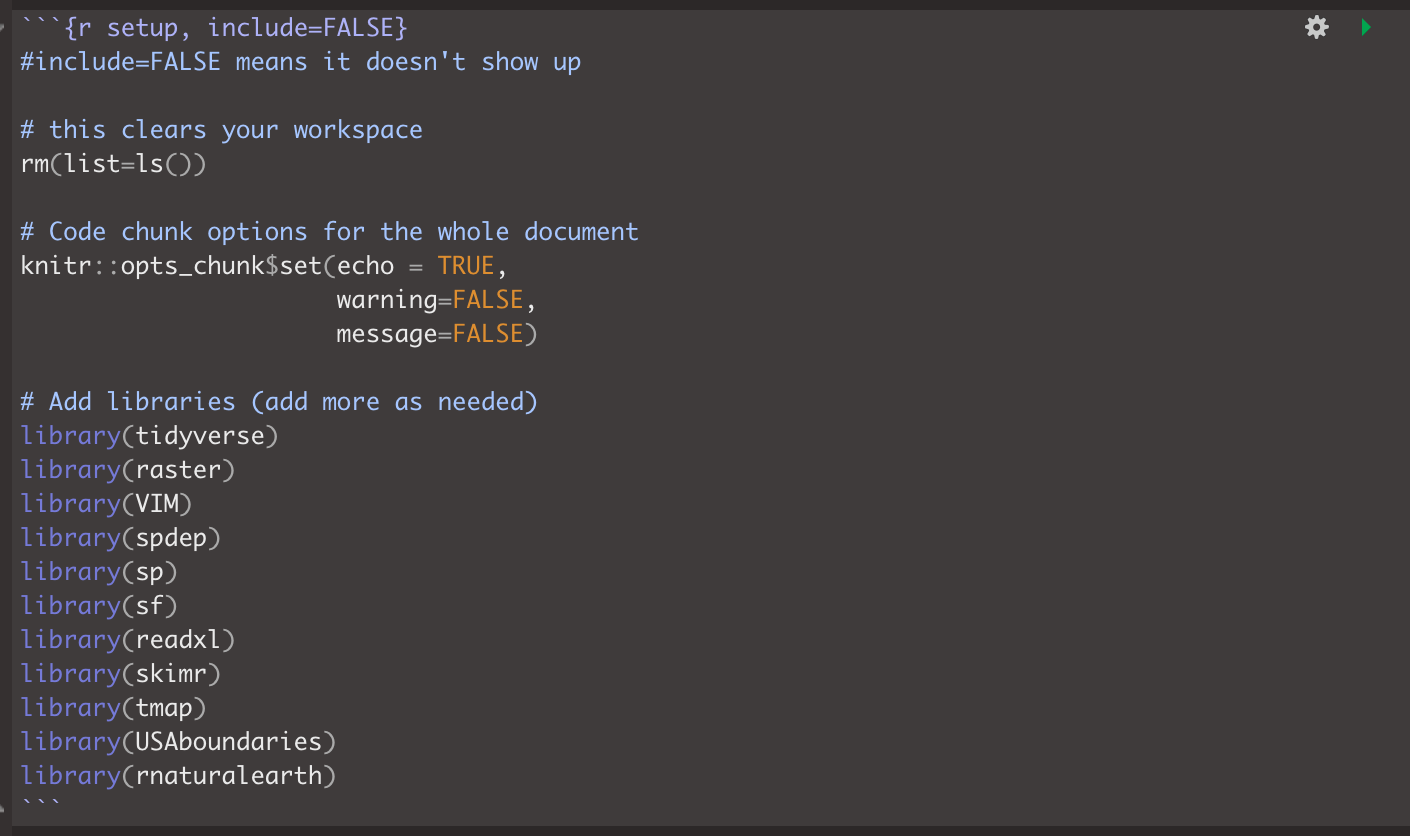
You will need BOTH the install.packages commands AND the remotes commandsEdit your top code chunk that looks like this, and add
library("tidycensus")to the list of libraries.
A3: Teach R your API key/password
You don’t need to type this password in every time you run R. Instead we will teach it to R once.
Run the command with the libraries. Now save everything
IN THE CONSOLE, type this command, but replace “YOUR API KEY GOES HERE” with the password you were given
# census_api_key("YOUR API KEY GOES HERE", install=TRUE,overwrite=TRUE)
# Here is an imaginary example, you need your own number from the e-mail
# census_api_key("d2a990f429205c51b54998ec58886c6cf01a7ef2", install=TRUE,overwrite=TRUE)This will now load the password.
CLOSE R-STUDIO AND RE-OPEN YOUR PROJECT FILE
B: Playing with census data
B1: Census data online
There are many inbuilt data-sets in R. One of the most powerful is that you have access to almost all of the US Census Data through the tidycensus package. Today we will be looking at data from the American Community survey.
Make a new heading called the American Community Survey Online
- Step 1:
Google the ACS and explain what it is, how often the data is collected and the sorts of data available. What is the population of this dataset?
- Step 2:
Follow Tutorial 6Ea on policy map. Explore what variables are available and see how the maps look (for those with US projects, think about whether there are variables that might be useful).
- Step 3:
For a US State of your choice, make a professional looking map of a census/ACS variable of your choice. Either save/export the map (you might need legacy mode) or take a good looking screenshot. Then include the picture here in your report.
Underneath the plot, explain:
- What this variable shows about your chosen state.
- What patterns are there and are they dependent on your unit/scale of observation (e.g. autocorrelation)
- What process might have caused those patterns
B1: Census data in R
We will now download and explore some census data in R.
- Step 4:
Use Tutorial 6Eb and Tutorial 6Ec to download the following data into R, save it as something sensible
- State: Iowa
- Survey: ACS 5 year collected in 2017
- Scale: County
- Variables: med.income (“B19013_001) ; total.population (”B05012_001”); income.gt75 (“B06010_011”)
- Step 5:
Use Tutorial 6Ed to create a column with the percentage of people making more than $750000.
- Step 6:
Use Tutorial 6Ed - scroll down and the tmap tutorial from Lab 4 to make a professional plot of this
C: Social vulnerability and Moran’s I Tutorial
This section applies what we have learned to a real life scenario (vulnerability modelling in the USA) and introduces the concept or Moran’s I. It will also allow us to read in shapefiles.
It is set out as a worked example, with the steps you need to take at the end
What is SVI?
The Centers for Disease Control and Prevention Social Vulnerability Index (SVI) was created to help public health officials and emergency response planners identify and map the communities that will most likely need support before, during, and after a hazardous event.
SVI indicates the relative vulnerability of every U.S. Census tract. Census tracts are subdivisions of counties for which the Census collects statistical data. SVI ranks the tracts on 15 social factors, including unemployment, minority status, and disability, and further groups them into four related themes. Thus, each tract receives a ranking for each Census variable and for each of the four themes, as well as an overall ranking.
I am going to use this data for a specific state to look at the spatial distribution of some of these variables.
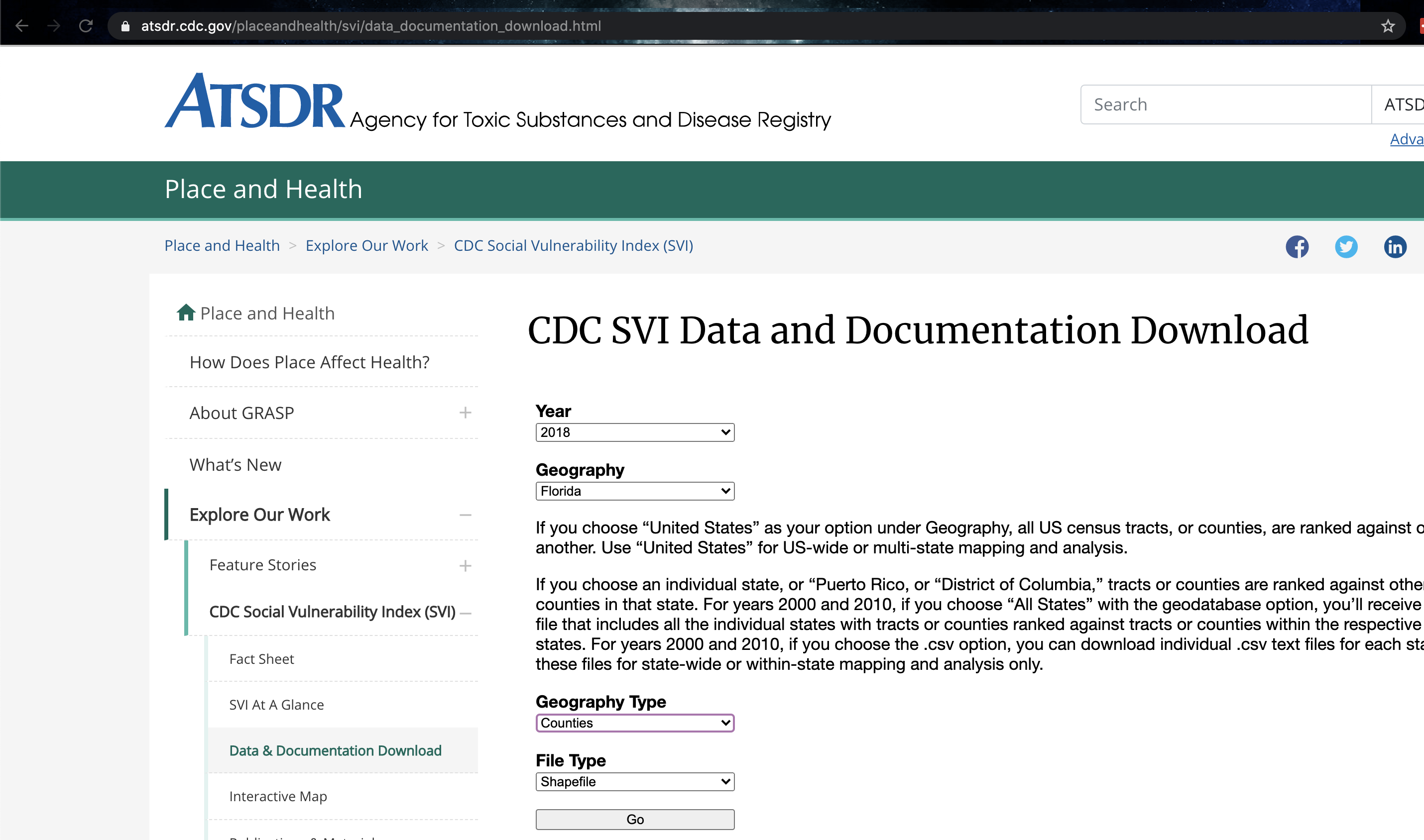
Download the data
First I will find and download the data. I found the SVI data at
The documentation to understand what the column headings of the data can be found at:
I then downloaded county level data shapefile for Florida for 2018 as an ESRI shapefile. I saved this to my lab 6 folder, then unzipped it.
Read the data into R
I used to read the shapefile into R.
# This reads in the shapefile containing the SVI Data and saves it to an sf variable called SVI
SVI.sf.lonlat <- st_read("SVI2018_FLORIDA_county.shp")## Reading layer `SVI2018_FLORIDA_county' from data source
## `/Users/hlg5155/Dropbox/My Mac (E2-GEO-WKML011)/Documents/GitHub/Teaching/Geog364-2021/SVI2018_FLORIDA_county.shp'
## using driver `ESRI Shapefile'
## Simple feature collection with 67 features and 125 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -87.63494 ymin: 24.5231 xmax: -80.03136 ymax: 31.00089
## Geodetic CRS: NAD83I will also use the us_states command from the USAboundaries package to download the border of Florida. If you see warnings about an old crs , ignore them
# This downloads the US state border data for my state, it's from the USAboundaries package
Stateborder.sf.lonlat <- us_states(states = "Florida",)Change the projection
Now let’s check the map projection of both and make sure they are the same or they won’t plot Tutorial 11 A
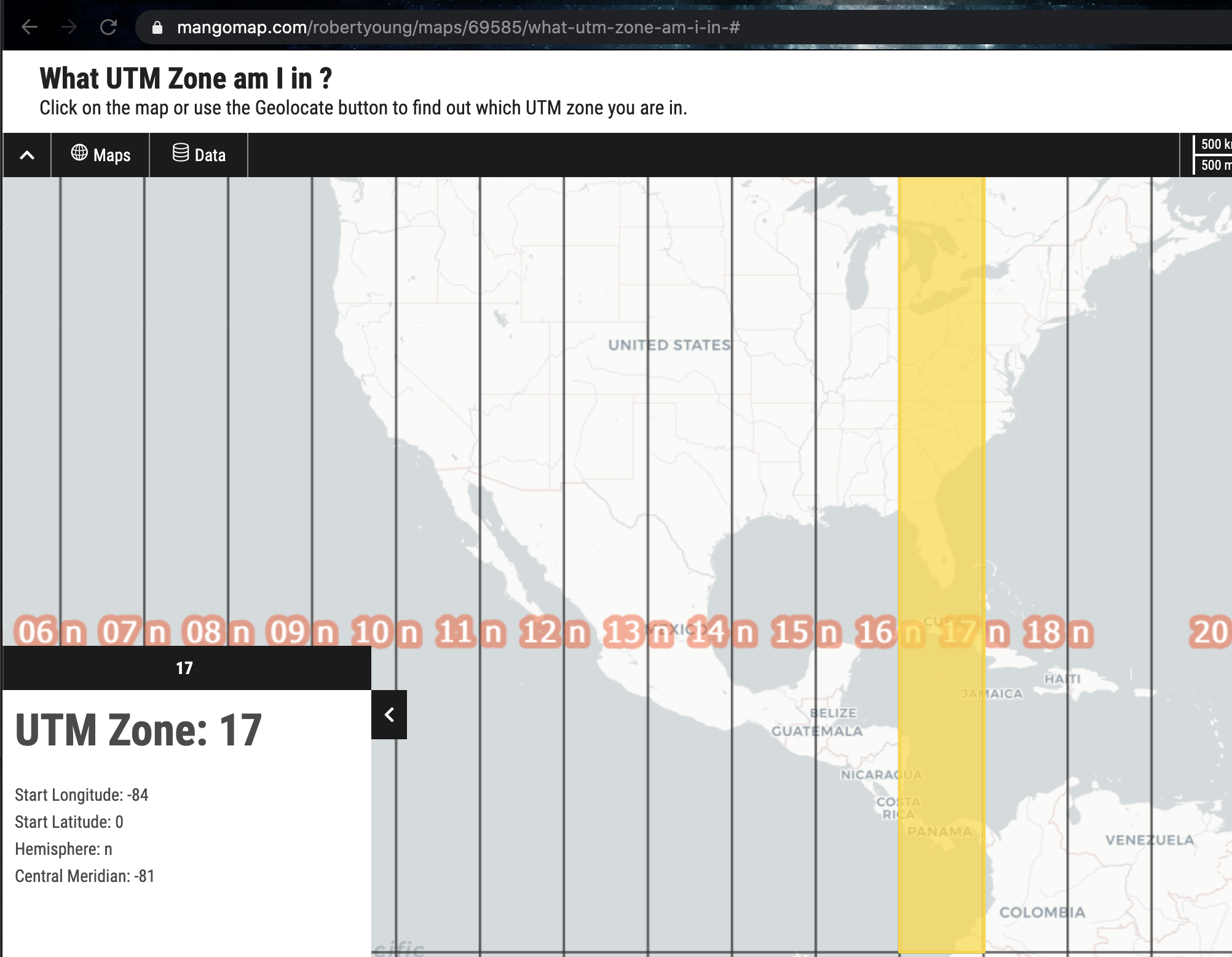
raster::projection(SVI.sf.lonlat)## [1] "+proj=longlat +datum=NAD83 +no_defs"raster::projection(Stateborder.sf.lonlat)## [1] "+proj=longlat +datum=WGS84 +no_defs"Although they are both equal, I’m now going to change them both to a UTM projection as it’s more robust. I found the code by selecting Florida UTM here:
Then checking the epsg code here:
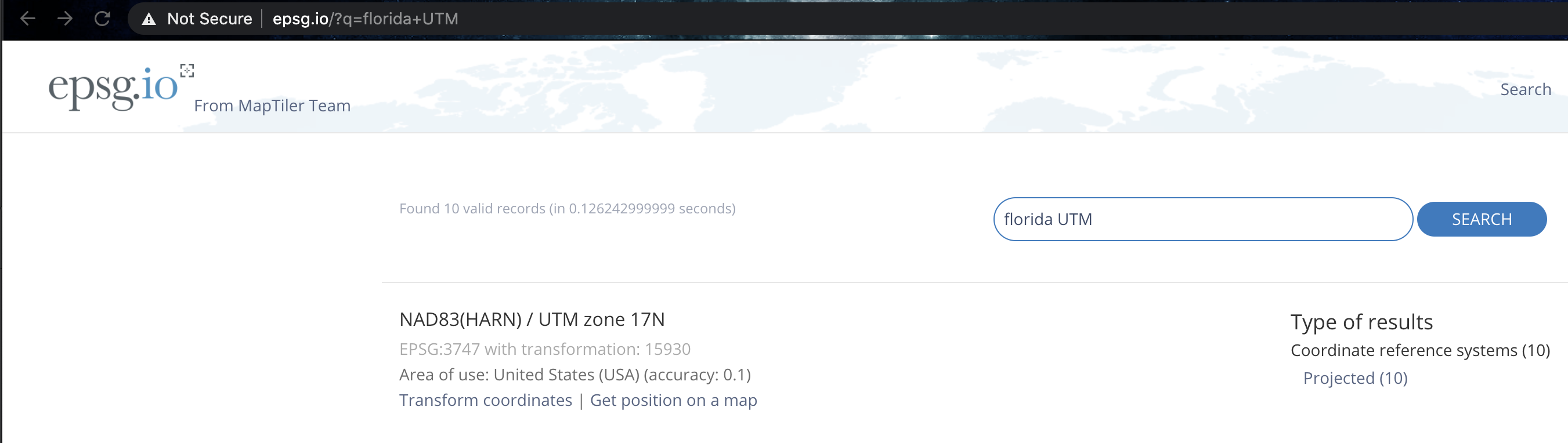
SVI.sf.utm <- st_transform(SVI.sf.lonlat,3747)
Stateborder.sf.utm <- st_transform(Stateborder.sf.lonlat,3747)and check it worked:
This :
raster::projection(SVI.sf.lonlat)## [1] "+proj=longlat +datum=NAD83 +no_defs"raster::projection(Stateborder.sf.lonlat)## [1] "+proj=longlat +datum=WGS84 +no_defs"should be different to this:
raster::projection(SVI.sf.utm)## [1] "+proj=utm +zone=17 +ellps=GRS80 +units=m +no_defs"raster::projection(Stateborder.sf.utm)## [1] "+proj=utm +zone=17 +ellps=GRS80 +units=m +no_defs"Explore the data
Now I can explore the dataset. I have already looked at the documentation and seen that there are many columns I can look at. I can see these by showing the column names here, or by clicking its name in the Environment tab.
names(SVI.sf.utm)## [1] "ST" "STATE" "ST_ABBR" "COUNTY" "FIPS"
## [6] "LOCATION" "AREA_SQMI" "E_TOTPOP" "M_TOTPOP" "E_HU"
## [11] "M_HU" "E_HH" "M_HH" "E_POV" "M_POV"
## [16] "E_UNEMP" "M_UNEMP" "E_PCI" "M_PCI" "E_NOHSDP"
## [21] "M_NOHSDP" "E_AGE65" "M_AGE65" "E_AGE17" "M_AGE17"
## [26] "E_DISABL" "M_DISABL" "E_SNGPNT" "M_SNGPNT" "E_MINRTY"
## [31] "M_MINRTY" "E_LIMENG" "M_LIMENG" "E_MUNIT" "M_MUNIT"
## [36] "E_MOBILE" "M_MOBILE" "E_CROWD" "M_CROWD" "E_NOVEH"
## [41] "M_NOVEH" "E_GROUPQ" "M_GROUPQ" "EP_POV" "MP_POV"
## [46] "EP_UNEMP" "MP_UNEMP" "EP_PCI" "MP_PCI" "EP_NOHSDP"
## [51] "MP_NOHSDP" "EP_AGE65" "MP_AGE65" "EP_AGE17" "MP_AGE17"
## [56] "EP_DISABL" "MP_DISABL" "EP_SNGPNT" "MP_SNGPNT" "EP_MINRTY"
## [61] "MP_MINRTY" "EP_LIMENG" "MP_LIMENG" "EP_MUNIT" "MP_MUNIT"
## [66] "EP_MOBILE" "MP_MOBILE" "EP_CROWD" "MP_CROWD" "EP_NOVEH"
## [71] "MP_NOVEH" "EP_GROUPQ" "MP_GROUPQ" "EPL_POV" "EPL_UNEMP"
## [76] "EPL_PCI" "EPL_NOHSDP" "SPL_THEME1" "RPL_THEME1" "EPL_AGE65"
## [81] "EPL_AGE17" "EPL_DISABL" "EPL_SNGPNT" "SPL_THEME2" "RPL_THEME2"
## [86] "EPL_MINRTY" "EPL_LIMENG" "SPL_THEME3" "RPL_THEME3" "EPL_MUNIT"
## [91] "EPL_MOBILE" "EPL_CROWD" "EPL_NOVEH" "EPL_GROUPQ" "SPL_THEME4"
## [96] "RPL_THEME4" "SPL_THEMES" "RPL_THEMES" "F_POV" "F_UNEMP"
## [101] "F_PCI" "F_NOHSDP" "F_THEME1" "F_AGE65" "F_AGE17"
## [106] "F_DISABL" "F_SNGPNT" "F_THEME2" "F_MINRTY" "F_LIMENG"
## [111] "F_THEME3" "F_MUNIT" "F_MOBILE" "F_CROWD" "F_NOVEH"
## [116] "F_GROUPQ" "F_THEME4" "F_TOTAL" "E_UNINSUR" "M_UNINSUR"
## [121] "EP_UNINSUR" "MP_UNINSUR" "E_DAYPOP" "Shape_STAr" "Shape_STLe"
## [126] "geometry"There are lots more non-spatial plots I can make, but for now I will move onto maps.
Today I am going to use tmap. As you can see and know from previous tutorials, a plot is built up in layers using the “+” symbol to connect them. Each tm_shape line identifies some data you want to plot, then the indented lines afterwards plot it.
I have chosen to plot one of the many variables that are available to me:E_TOTPOP. From the documentation I found this represents the population total in each county:
tm_shape(SVI.sf.utm) +
tm_polygons(col="E_TOTPOP", style="quantile",
border.col = "black",
palette="Spectral") +
tm_legend(outside = TRUE) +
tm_shape(Stateborder.sf.utm) +
tm_borders() +
tm_layout(main.title = "Population", main.title.size = 0.95)Creating a spatial weights matrix
For the rest of this lab I am going to focus on population density.
First, I look to see if the population density data looks like it clusters or is dispersed. I can also look at other data to understand why this might be the case (e.g. is there some underlying reason why our data looks this way). From my perspective and the color scale, it does look like there is clustering of high population areas.
As described in Lab 5, before we can formally model the spatial dependency shown in the above map, we must first cover how neighborhoods are spatially connected to one another. That is, what does “near” mean when we say “near things are more related than distant things”?
For each census tract, we need to define
- What counts as its neighbor (connectivity)
- How much does each neighbor matter? (spatial weights)
To do this we again calculate the spatial weights matrix.
However, this is where R gets annoying - we need an sp version of our data:
SVI.sp.utm <- as(SVI.sf.utm,"Spatial")
# calculate the spatial weights matrix
spatial.matrix.rook <-poly2nb(SVI.sp.utm, queen=F)
plot(SVI.sp.utm, border='blue')
plot(spatial.matrix.rook, coordinates(SVI.sp.utm), col='black', lwd=2, add=TRUE)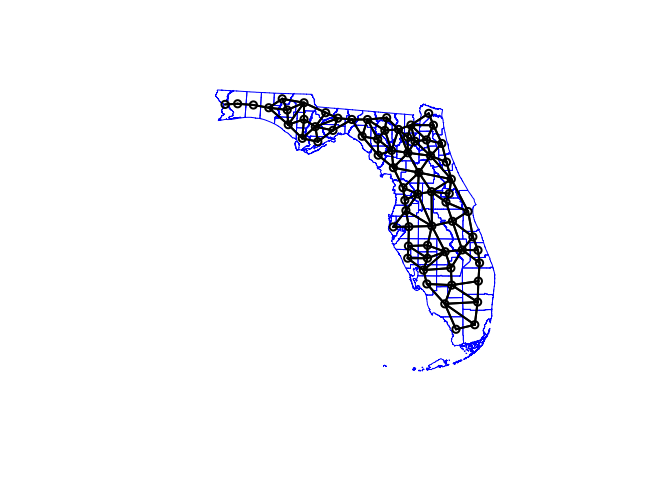
We can then assign weights to each one based on whether it is a neighbour or not. Again, I am just using rook’s contingency, a binary classification of 1 if a county is a neighbour and 0 if not.
# calculate the spatial weights
weights.rook <- nb2listw(spatial.matrix.rook, style='B',
zero.policy = T)Moran’s scatterplot
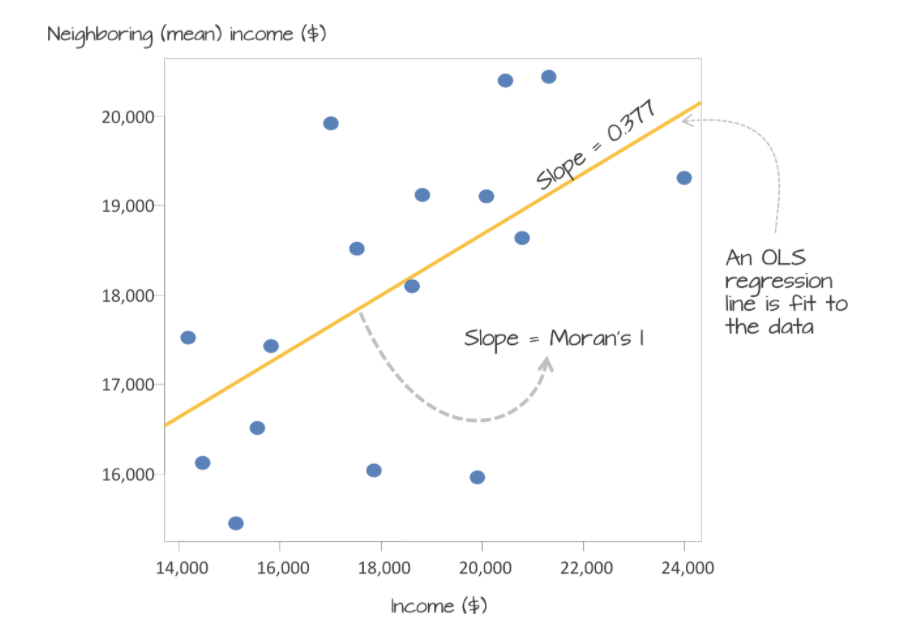
Now we want to use our neighbours to assess whether there is any clustering. so I will calculate something called a Moran’s scatterplot. This plots the value of our variable for each county/unit, against the average value of its “neighbours” (where neighbours is defined by the spatial weights matrix).
For example:
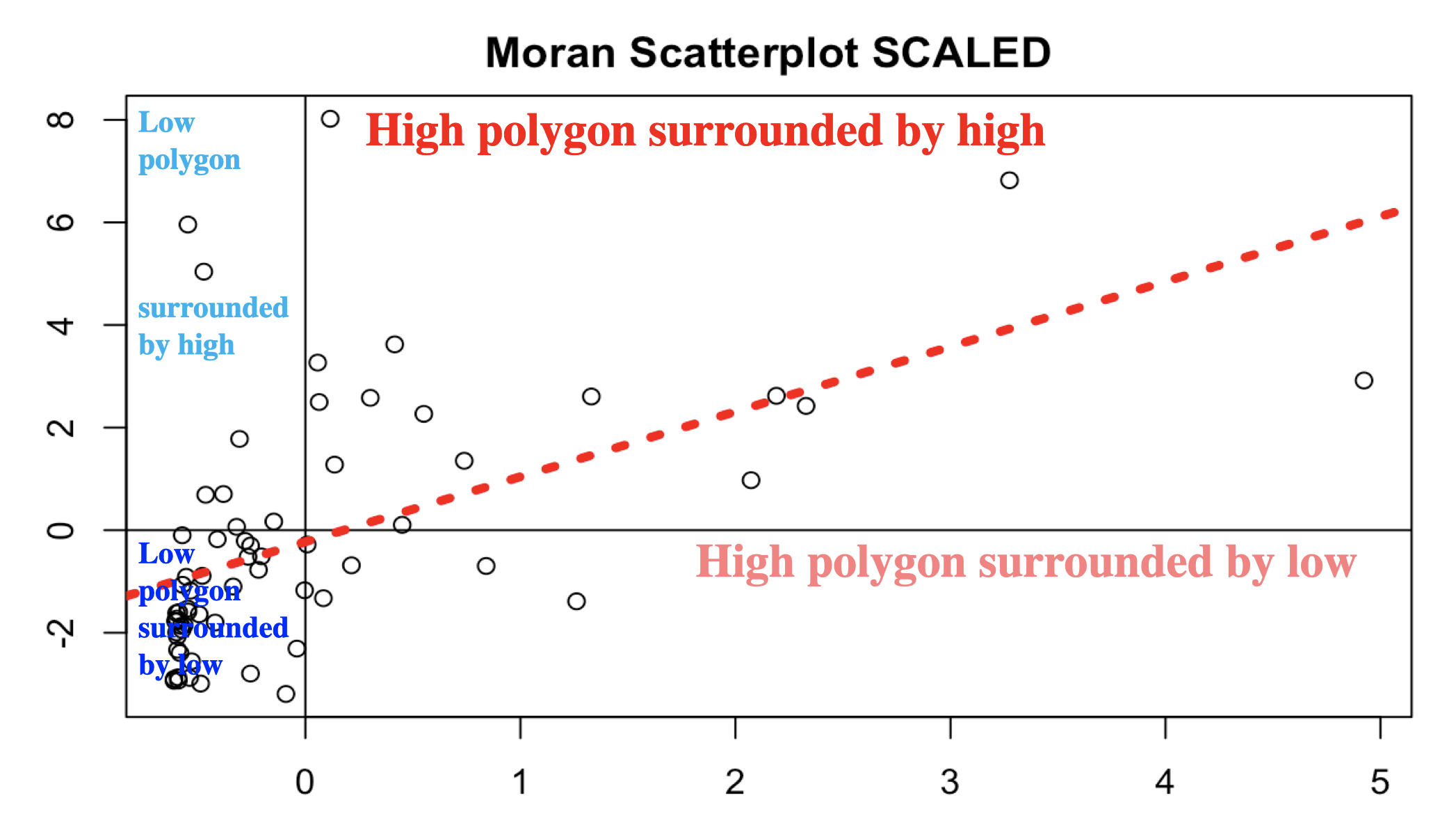
Here is our attempt: In a county with a high population, surrounded by counties with a high population would be in the top right.
## and calculate the Moran's plot
moran.plot(SVI.sp.utm$E_TOTPOP, weights.rook,
xlab = "Population",
ylab = "Neighbors Population",
labels=SVI.sp.utm$COUNTY,
zero.policy = T)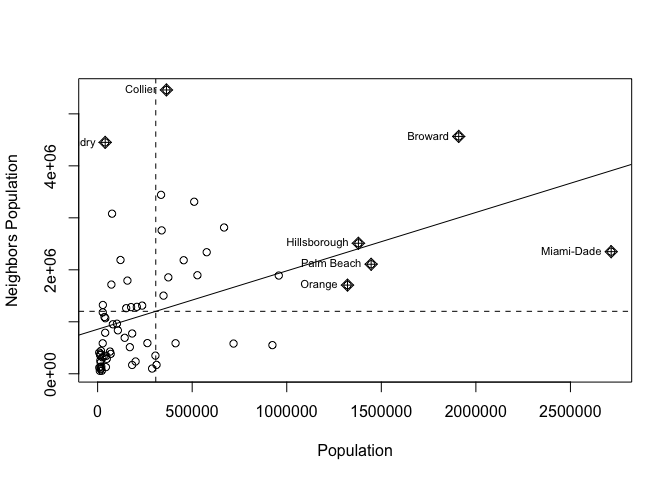
Here we can see that high population counties tend to be clustered together, but that there is not a perfect relationship. Miami Dade in particular is maybe skewing the relationship a little. (In join counts all our data was either TRUE or FALSE, so this scatterplot wouldn’t make sense)
Linking to autocorrelation
This now links directly to autocorrelation through the correlation of the plot.
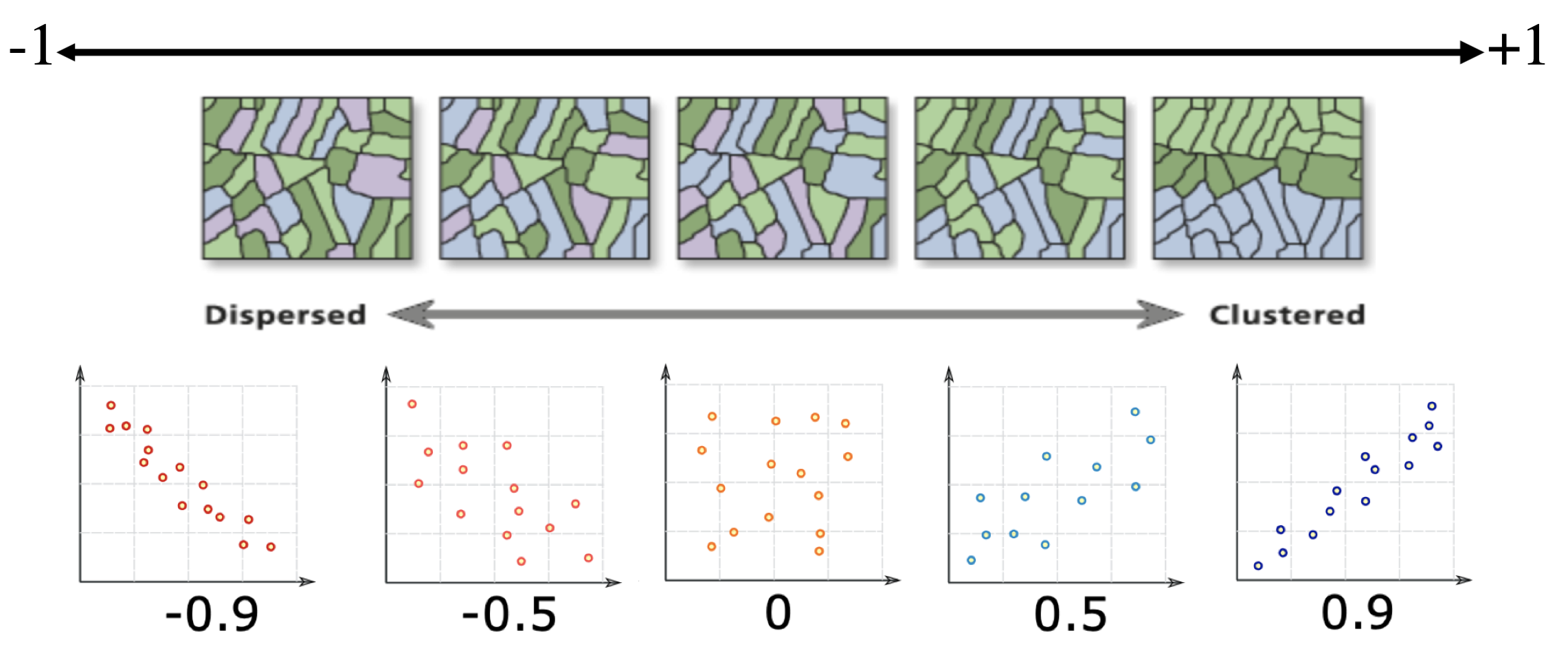
The “Moran’s I” global statistic is the correlation coefficient of the Moran’s I scatterplot (remember previous lectures)
Significance test
We can now test whether our data is significantly clustered/dispersed, using a Moran’s I hypothesis test. This assesses whether our data is unusually structured (e.g. clustered or dispersed) compared to a pattern generated by an IRP.
The easiest way to see this in R is to use the Moran.test command, which also assesses the significance of your result:
moran.test(SVI.sp.utm$E_TOTPOP, weights.rook,
zero.policy = T) ##
## Moran I test under randomisation
##
## data: SVI.sp.utm$E_TOTPOP
## weights: weights.rook
##
## Moran I statistic standard deviate = 4.205, p-value = 1.305e-05
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.297170683 -0.015151515 0.005516543We find that the Moran’s I is positive (0.30) and statistically significant (the p value is very small). Remember from lecture that the Moran’s I is simply a correlation, and correlations go from -1 to 1.
A 0.30 correlation is relatively high, indicating some clustering, but not a very strong signal. Moreover, we find that this correlation is statistically significant (p-value basically at 0).
D: Your own SVI analysis
Make a new heading called SVI. In here, I would like you to present a spatial autocorrelation analysis of your own.
This will be easier in week 2 after the lecture on Moran’s I. Your job is to repeat this tutorial in your own .rmd file but for a DIFFERENT STATE and for a DIFFERENT VARIABLE. (not Florida and not Population density). Ideally choose the state that you used for the census analysis and go for an interesting variable like RPL_THEME1 (look at the documentation to understand it!)
Your write up should include:
- A description of what the SVI data is and why it’s important (remember the documentation will help). You should include the unit of observation
- Why you chose the state that you did. Is there something interesting there you want to look at?
- All the relevant code to make the analysis work for you.
- What map projection you chose and why.
- An exploratory analysis of the data with good spatial maps, for example how does the pattern/process compare to the census data you downloaded earlier.
- A full Moran’s plot and hypothesis test with the results explained clearly in the text. You should clearly explain what Moran’s I is and how to interpret it.
For full grades, the code will also show some originality e.g. making the plots feel like “yours” (choosing your own color palettes, map backgrounds etc), including markdown elements such as references or equations as relevant, including section sub-headings and thoughtful analysis.
E. Above and beyond
Remember that an A is 93%, so you can ignore this section and still easily get an A. But here is your time to shine. Also, if you are struggling in another part of the lab, you can use this to gain back points.
To get the final 4 marks in the lab, you need to show me something new, e.g. you need to go above and beyond the lab questions in some way.
- You get 2/4 for doing something new in any way
- You get 4/4 for something really impressive
An easy example, try conducting a Moran’s analysis for your census data. Bonus marks if you can convert a column to TRUE/FALSE and do a join counts analysis on it!
Please tell us in your R script what you did!
F. Submitting your Lab
Remember to save your work throughout and to spell check your writing (left of the knit button). Now, press the knit button again. If you have not made any mistakes in the code then R should create a html file in your lab 6 folder which includes your answers. If you look at your lab 6 folder, you should see this there - complete with a very recent time-stamp.
In that folder, double click on the html file. This will open it in your browser. CHECK THAT THIS IS WHAT YOU WANT TO SUBMIT
Now go to Canvas and submit BOTH your html and your .Rmd file in Lab 6.
Lab 6 submission check-list
For all answers: Full marks = everything down at a high standard, in full sentences as appropriate with no parts of your answer missing. Imagine it as an example I use in class
HTML FILE SUBMISSION - 5 marks
RMD CODE SUBMISSION - 5 marks
MARKDOWN STYLE - 10 MARKS
We will start by awarding full marks and dock marks for mistakes.LOOK AT YOUR HTML FILE IN YOUR WEB-BROWSER BEFORE YOU SUBMIT
TO GET 13/13 : All the below PLUS your equations use the equation format & you use subscripts/superscript as appropriate
TO GET 12/13 - all the below:
- Your document is neat and easy to read.
- Answers are easy to find and paragraphs are clear (e.g. you left spaces between lines)
- You have written in full sentences, it is clear what your answers are referring to.
- You have used the spell check.
- You have used YAML code to make your work look professional (themes, tables of contents etc)
CODING STYLE - 10 MARKS
- You have managed to create all relevant code.
- Your code is neat & commented
- Variable names make sense.
- You have no spurious printed output from library loads or other code.
We grade this by first awarding full marks, then dropping points as mistakes are found or as coding gets messier.
ACS and POLICY MAP - 10 MARKS
You have clearly explained what ACS is, how often the data is collected and the sorts of data available. You have defined the population.
You have included an image (properly cropped/presented) of a professional map you made in Policy Map for a state of your choice
You have explained what your chosen variable shows about your chosen state, what patterns are there and whether they show autocorrelation. You have commented on process.
Census MAPS IN R - 10
You have read in the data, created a percentage column and made a professional looking plot.
SVI Analysis - 46
You have conducted an SVI analysis for your own state and variable, including
15 marks: Description
- A description of what the SVI data is and why it’s important (remember the documentation will help). You should include
- the unit of observation,
- why you chose the state that you did.
- what map projection you chose and why.
15 marks: Coding and maps
- An exploratory analysis of the data with good spatial maps, for example how does the pattern/process compare to the census data you downloaded earlier.
16 marks: Moran’s plot
- A full Moran’s plot and hypothesis test with the results explained clearly in the text. You should clearly explain what Moran’s I is and how to interpret it. You have included all steps, for example YOUR HYPOTHESES IN WORDS as well as maths, plus a full description of outcomes.
Above and beyond: 4 MARKS
- You get 2/4 for doing something new in any way
- You get 4/4 for something really impressive
An easy example, try conducting a Moran’s analysis for your census data. Bonus marks if you can convert a column to TRUE/FALSE and do a join counts analysis on it! [100 marks total]
Overall, here is what your lab should correspond to:
| Grade | % Mark | Rubric |
|---|---|---|
| A* | 98-100 | Exceptional. Not only was it near perfect, but the graders learned something. THIS IS HARD TO GET. |
| NA | 96+ | You went above and beyond |
| A | 93+: | Everything asked for with high quality. Class example |
| A- | 90+ | The odd minor mistake, All code done but not written up in full sentences etc. A little less care |
| B+ | 87+ | More minor mistakes. Things like missing units, getting the odd question wrong, no workings shown |
| B | 83+ | Solid work but the odd larger mistake or missing answer. Completely misinterpreted something, that type of thing |
| B- | 80+ | Starting to miss entire/questions sections, or multiple larger mistakes. Still a solid attempt. |
| C+ | 77+ | You made a good effort and did some things well, but there were a lot of problems. (e.g. you wrote up the text well, but messed up the code) |
| C | 70+ | It’s clear you tried and learned something. Just attending labs will get you this much as we can help you get to this stage |
| D | 60+ | You attempt the lab and submit something. Not clear you put in much effort or you had real issues |
| F | 0+ | Didn’t submit, or incredibly limited attempt. |
Website created and maintained by Helen Greatrex. Website template by Noli Brazil