TUTORIAL Regression
In this tutorial, we are going to look at regression models to assess what causes census tracts to contain more people who make over $75000. We are also going to assess if the residuals (what is left over) from our models have spatial autocorrelation (bad).
Getting the data
This tutorial builds on the example from the LISA tutorial. So IF YOU ARE DOING LAB 6 YOU HAVE ALREADY DONE THIS AND MOVE ONTO “BASICS”
Code to load the example data
We can load your data from the census and tidy up, before plotting
FOR THIS CODE CHUNK, set results=‘hide’ as a code-chunk option, or it will swamp your knit: {r, results=‘hide’}
# THIS WILL NOT WORK IF YOU DIDN'T RUN YOUR API KEY CODE & RESTART R-STUDIO LAST LAB
# Download Illinois ACS data at census tract level for my chosen variables, using tidycensus
IL.Census.sf <- get_acs(
geography = "tract",
year = 2017,
variables = c(
total_pop = "B05012_001", # total population
total_house = "B25001_001", #total housing units
income.gt75 = "B06010_011",# number of people making > 75000 USD
med.income = "B19013_001", #median income
total.foreignppl = "B05012_003", #number of foreign born people
total.BAdegree = "B15012_001" , #total with at least a bachelors degree
total.workhome = "B08101_049", #number who work from home#total housing units
house.mean_age = "B25035_001", #average house age
house.mean_beds = "B25041_001", #total homes number of beds in the house
housetotal.owneroccupied = "B25003_002", #total homes owner occupied
housetotal.broadband = "B28002_004"), #total homes with broadband access
state = "IL",
survey = "acs5",
geometry = TRUE,
output = "wide",
cache_table = TRUE)We also need to change the map projection. As we’re focusing on a single city, lets use a local UTM projection, which has EPSG code 26916.
To find one for your area, FIRST find your city’s UTM zone, then google which EPSG code you need for it. (the EPSG code is the shortcut number to tell R what projection we are using)
- https://mangomap.com/robertyoung/maps/69585/what-utm-zone-am-i-in-
- There’s also a great tutorial here on choosing the best map projection https://source.opennews.org/articles/choosing-right-map-projection/
# Change the map projection to Albers equal projection,
# then remove empty polygons (lakes etc) and fix any broken geometry
IL.Census.sf <- IL.Census.sf %>%
st_transform(26916) %>%
st_make_valid()You can see the data summarized here. Each column ending in E means the estimate of the value in each census tract and the column ending in M means the margin of error.
For more advanced work we probably want to keep the error columns. But here let’s remove them.
# Remove and rename error columns
IL.Census.sf <- IL.Census.sf %>%
dplyr::select(
GEOID,
NAME,
total_pop = total_popE,
total_house = total_houseE,
income.gt75 = income.gt75E,
med.income = med.incomeE,
total.foreignppl = total.foreignpplE,
total.BAdegree = total.BAdegreeE,
total.workhome = total.workhomeE,
house.mean_age = house.mean_ageE,
house.mean_beds = house.mean_bedsE,
housetotal.owneroccupied = housetotal.owneroccupiedE,
housetotal.broadband = housetotal.broadbandE,geometry )Rather than looking at the total population, it makes sense to scale by the size of each tract, so that bigger tracts don’t skew our results. We want:
- the population density (e.g. total_pop / Area)
- the percentage of people earning over $75K (e.g. income.gt75 /
total_pop)
# Find the areas in each county & change the units from metres squared to km squared
IL.Census.sf$Area <- st_area(IL.Census.sf)
IL.Census.sf$Area <- as.numeric(set_units(IL.Census.sf$Area,"km^2"))
# Now work out percentage ppl and homes rather than totals
IL.Census.sf <- IL.Census.sf %>%
mutate(
pop.density_km2 = total_pop / Area,
house.density_km2 = total_house / Area,
percent.income.gt75 = income.gt75 / total_pop,
percent.foreignppl = total.foreignppl / total_pop,
percent.BAdegree = total.BAdegree / total_pop,
percent.workhome = total.workhome / total_pop,
housepercent.owneroccupied = housetotal.owneroccupied / total_house,
housepercent.broadband = housetotal.broadband / total_house)
# Finally select the final columns we want
IL.Census.sf <- IL.Census.sf %>%
dplyr::select(
GEOID, NAME, Area,
total_pop, pop.density_km2,
total_house, house.density_km2,
income.gt75, percent.income.gt75,
med.income, house.mean_age,
percent.foreignppl, percent.BAdegree,
percent.workhome, housepercent.broadband,
housepercent.owneroccupied)Now let’s crop to the Chicago metropolitan area
# Get the Chicago city limits
cb.sf <- core_based_statistical_areas(cb = TRUE, year=2017)
Chicago.city.sf <- filter(cb.sf, grepl("Chicago", NAME))
# and set the projection to be identical to the census data
Chicago.city.sf <- Chicago.city.sf %>%
st_transform(26916) %>%
st_make_valid()
# subset the Illinois census data with the Chicago city limits
Chicago.Census.sf <- ms_clip(target = IL.Census.sf,
clip = Chicago.city.sf,
remove_slivers = TRUE)Finally, let’s remove any empty fields
# remove missing data and/or census tracts with no ppl in
Chicago.Census.sf <- Chicago.Census.sf %>%
filter(pop.density_km2 > 0) %>%
filter(!st_is_empty(geometry)) %>%
st_make_valid()and we’re up to date!
STEP 1 Regression Basics
Theory Refresh (don’t skip!)
If none of the summary below makes sense, this is a great overview
<
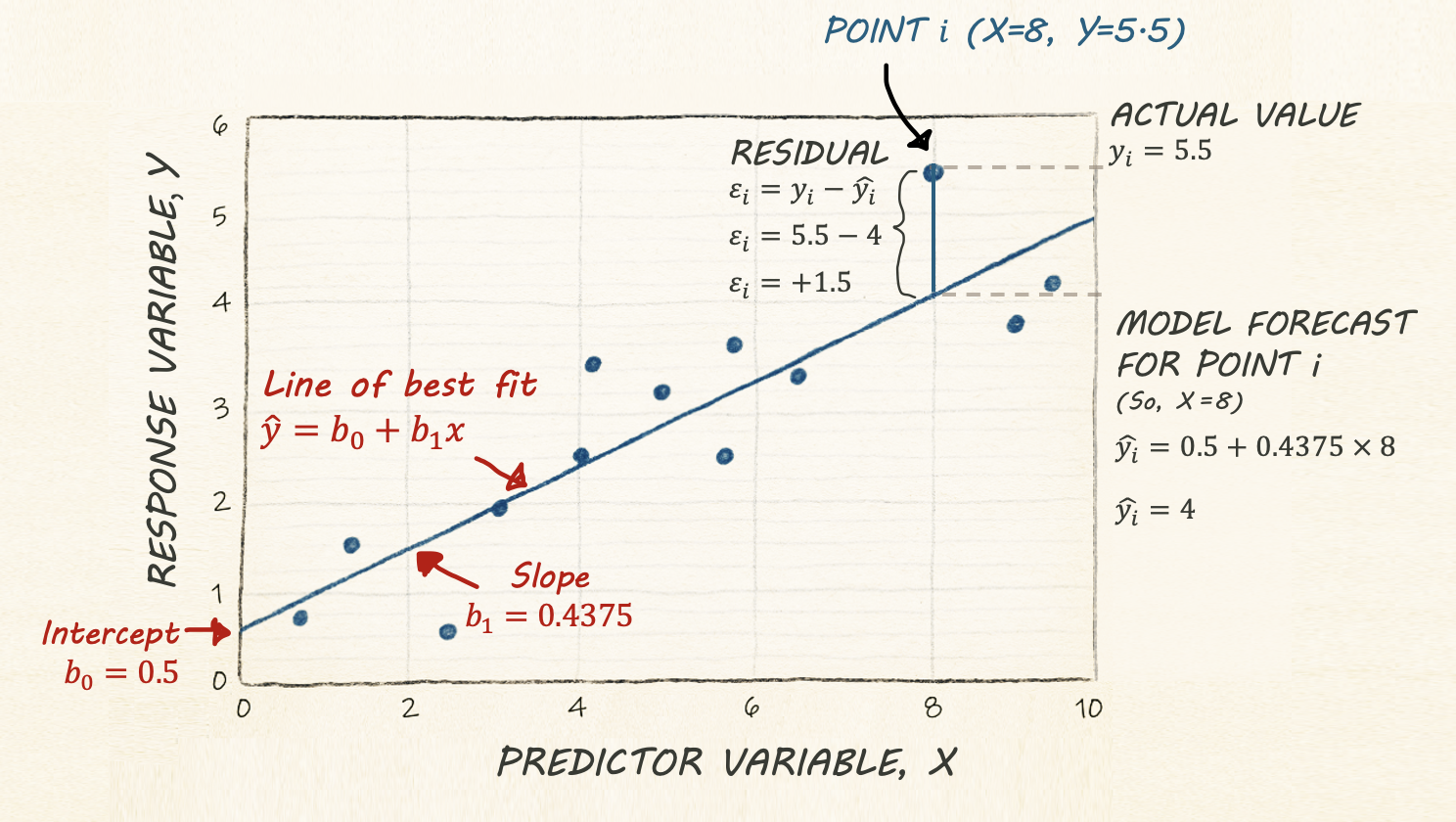
Regression helps us understand how one variable changes in relation to another. A simple regression line shows the general trend between two variables (the “line of best fit”), and gives us a way to describe that trend using an equation:
\[ \hat{y} = b_0 + b_1 x \]
Here,
\(\hat{y}\) is the predicted value of our response variable, y for any given value of our predictor variable, x. The little hat on top means “predicted/estimated”
\(b_0\) is the intercept - the value of the line when it crosses x=0.
\(b_1\) refers to the slope or gradient of the line. e.g. how much does y increase for a given x.
Finally, we know that value of y for every object in our study isn’t going to end up exactly on the line. So the value of y for an individual object (called i) can be written as the predicted value plus the residual (the amount left over), \(\varepsilon_i\) :
\[ y_i = \hat{y_i} + \varepsilon_i \]
Simple Linear Regression Example - Model Setup
Building on the LISA tutorial, suppose we want to understand what influences the percentage of people earning more than $75,000 in each census tract in Chicago.
Object of analysis: A single census tract
‘Strict’ population: All census tracts within Chicago city limits during the year 2020.
‘Inferrable’ population: Depends on context, but probably anywhere in a US metropolitan area in the last decade or so?
Response variable, y (the thing we are trying to predict) : Percentage of people earning more than $75000 in each census tract.
The ecological Fallacy
Note - I really want to explore whether people who make over $75000 are more likely to live in places with higher population density (say “downtown”).
But we don’t have data for individual people!
ALL WE CAN TEST IS: Why do CENSUS TRACTS have a higher percentage of households earning more than $75,000?
Mixing these two object-of-analyses up is called the ecological fallacy. The ecological fallacy happens when we take a pattern seen in groups and assume it must also hold for the individuals inside those groups.
For example, if neighbourhoods with high population density also have a higher percentage of households earning more than $75,000, that does not mean any particular high-income person prefers dense neighbourhoods. Group averages can hide a lot of variation, and individuals often behave very differently from the overall pattern.
The key point: Relationships measured at the group level do not automatically apply to individuals.
Tidy your data
This will stop you going insane.
First, let’s tidy our table to get rid of any columns we DEFINITELY don’t need. I’m removing most of the “total” columns because they will be dependent on census tract size. I’m also putting my response variable at the start so I don’t go insane.
# Finally select the final columns we want
Chicago.Census.sf <- Chicago.Census.sf %>%
dplyr::select(
GEOID, NAME,
percent.income.gt75,
Area,
total_pop,
pop.density_km2,
total_house,
med.income,
house.mean_age,
percent.foreignppl,
percent.BAdegree,
percent.workhome,
housepercent.broadband,
housepercent.owneroccupied)Choosing a predictor variable
Lets say I didnt care specically about population density. We want to understand what variables influence our response variable.
We have many potential predictor columns! One quick check is to look at the correlation coefficient.
# Filter to a new data frame with only numeric columns
# Remove all rows with NA (cheat for the lab)
Chicago.Census.numeric <- Chicago.Census.sf |>
st_drop_geometry() |>
dplyr::select(where(is.numeric)) |>
na.omit()
# calculate all the correlation coefficients against the "percent.income.gt75" column
cor_vector <- cor(Chicago.Census.numeric)["percent.income.gt75", , drop = FALSE]
# and make an initial plot
corrplot(cor_vector, method = "number",
addshade="all", cl.pos="n",
is.corr = TRUE, number.cex =.7)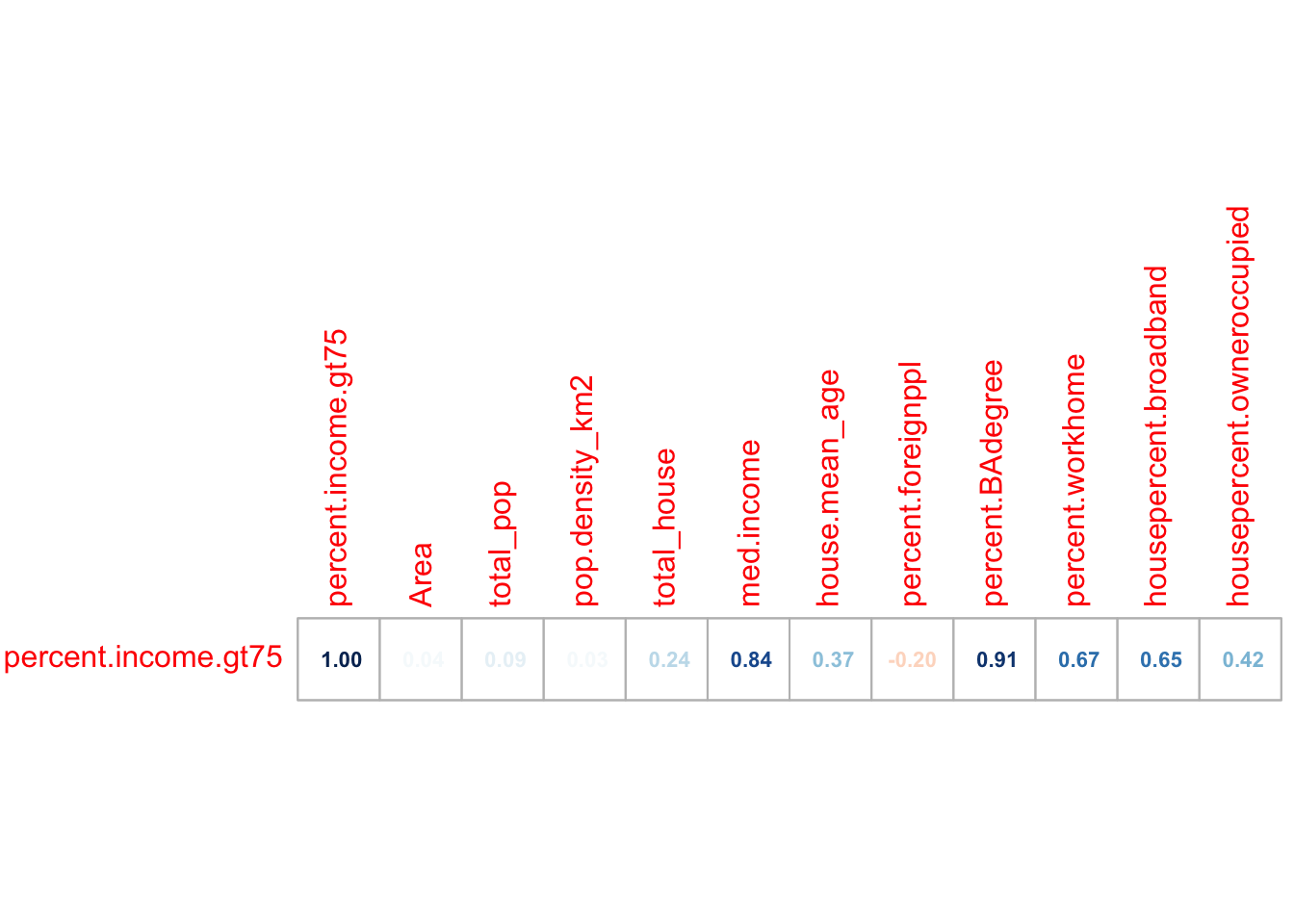
This plot shows the correlation coefficient between the percent.income > 75K and every other variable and gives us an initial feel for which variables predict our response.
Initial Scatterplots
First, let’s have a look at the scatterplot. We can make a basic scatterplot using the plot command. But just as easily, we can make an interactive plot using ggplot and plotly.
If you want some tutorials on customising these plots see here
For example here is the scatterplot for population density.
p <- Chicago.Census.sf %>%
ggplot(aes(
x = pop.density_km2,
y = percent.income.gt75,
label = NAME
)) +
geom_point(size = 1, alpha = 0.5) +
labs(
x = "Census tract population density (per km²)",
y = "% households per tract with income > $75k USD"
) +
theme_bw(base_size = 10)
ggplotly(p)We have a problem! This is why it’s good to plot the data!!
Deal with the outlier (you might not need this)
Our results are dominated by one huge outlier.. Click on it and you will see that it’s census tract 307.02! (mouse over it). The easiest way I could think to find it was to just look at any row where the population density was over 150000 ppl per km2.
OK so the issue is with Census Tract 307.02 in Cook County.
I then googled this census tract name, which took me here https://censusreporter.org/profiles/14000US17031030702-census-tract-30702-cook-il/
It looks like some apartments?? So I googled the location and looked at streetview to find this:

The entire census tract is one set of high-rise apartments, so of course this census tract has a ridiculously high population density, there are thousands of people living in a tiny area.
In that case, the next question is what do we do? We could:
Remove it and say it’s “bad data”.
Remove it and treat it as a special case
Leave it in.
The first option is inappropriate because there’s nothing wrong with the data. However, I think it would be reasonable to remove this census tract and study it separately as a special case. My reasoning is because it’s unlikely the data is independent. It’s only one or two buildings, and they’re likely to be full of apartments that are all likely to be tailored to the same financial demographic of people.
So I shall remove it
# I want to keep everything LESS than 150000
Chicago.Census.sf <- Chicago.Census.sf[Chicago.Census.sf$pop.density_km2 < 150000,] This gives some improvement, but not much!
# Make an interactive plot
p <- Chicago.Census.sf %>%
ggplot(aes(
x = pop.density_km2,
y = percent.income.gt75,
label = NAME
)) +
geom_point(size = 1, alpha = 0.5) +
labs(
x = "Census tract population density (per km²)",
y = "% households per tract with income > $75k USD"
) +
theme_bw(base_size = 10)
ggplotly(p)We should also recalculate the correlation coefficients
# Filter to a new data frame with only numeric columns
# Remove all rows with NA (cheat for the lab)
Chicago.Census.numeric <- Chicago.Census.sf |>
st_drop_geometry() |>
dplyr::select(where(is.numeric)) |>
na.omit()
# calculate all the correlation coefficients against the "percent.income.gt75" column
cor_vector <- cor(Chicago.Census.numeric)["percent.income.gt75", , drop = FALSE]
# and make an initial plot
corrplot(cor_vector, method = "number",
addshade="all", cl.pos="n",
is.corr = TRUE, number.cex =.7)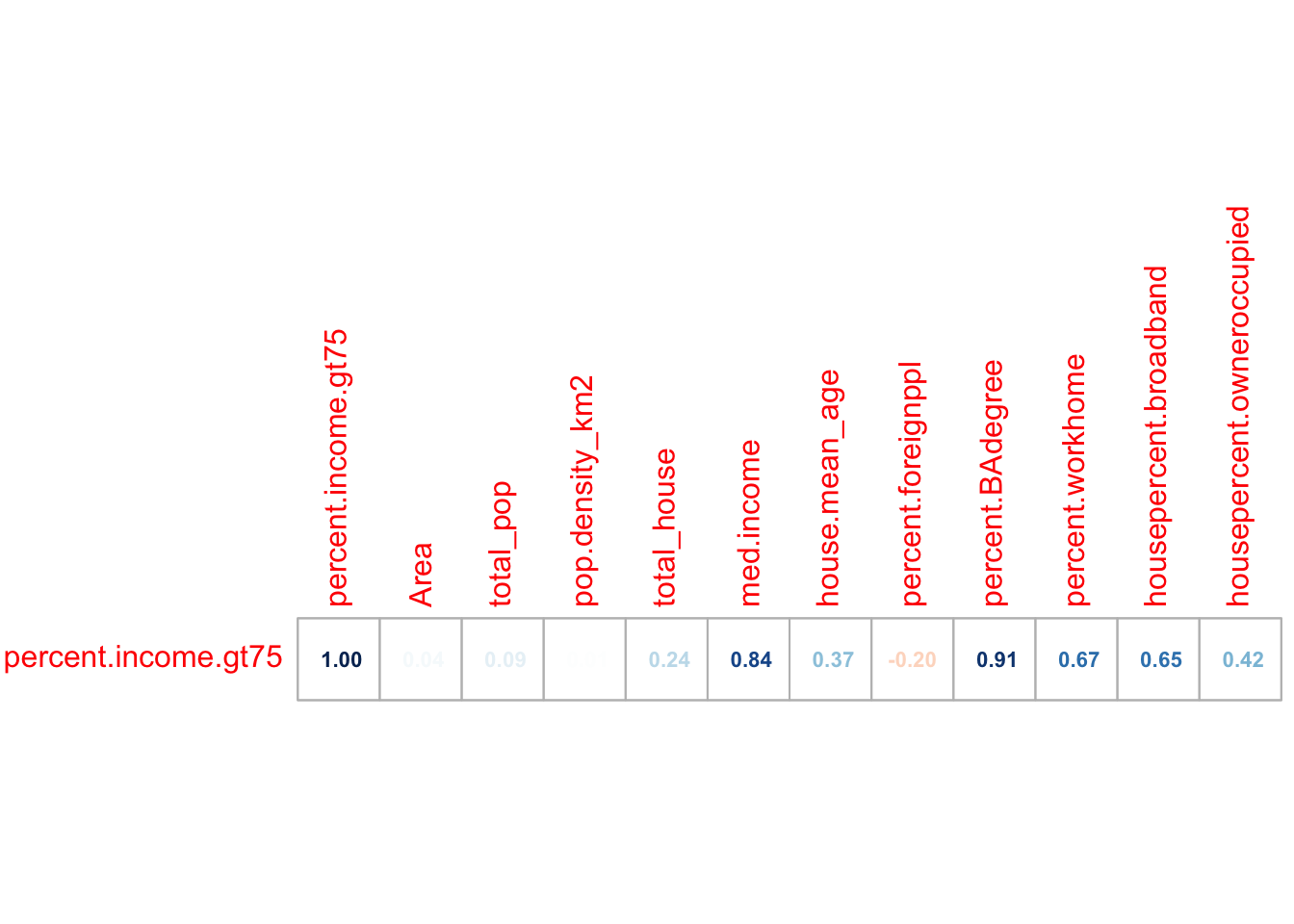
So in this case, removing that one outlier did change some values but not by much. Things like the percentage of people in the census tract with a bachelors degree were MUCH more influential
# Make an interactive plot
p <- Chicago.Census.sf %>%
ggplot(aes(
x = percent.BAdegree,
y = percent.income.gt75,
label = NAME
)) +
geom_point(size = 1, alpha = 0.5) +
labs(
x = "% households per tract with degree",
y = "% households per tract with income > $75k USD"
) +
theme_bw(base_size = 10)
ggplotly(p)I keep plotting the data and predictors until I am happy, remembering to provide evidence in the text for my choices.
STEP 2 REGRESSION MODELLING
Model 1
Here is my final choice of variables for model 1.
Object of analysis: A single census tract
‘Strict’ population: All census tracts within Chicago city limits during the year 2020.
Response variable, y (the thing we are trying to predict) : Percentage of people earning more than $75000 in each census tract.
Predictor variable, x : percent.BAdegree Percentage of people with a degree in each census tract.
Fit the model
We can fit a line of best fit / linear model using the
lm command. Inside the command type
- y ~ x where y and x are the COLUMN NAMES of your response and
predictor variables. The ~ means “can be explained by”
e.g. percent.income.gt75 can be explained by percent.BAdegree.
- For data, add the name of your dataset.
na.excludemeans ignore any missing values.
Model summary
If you type summary(modelname), where modelname is the name YOU chose for your model, then you’ll see a load of statistics. Don’t worry about most of them, but you can see here how to find the slope and intercept.
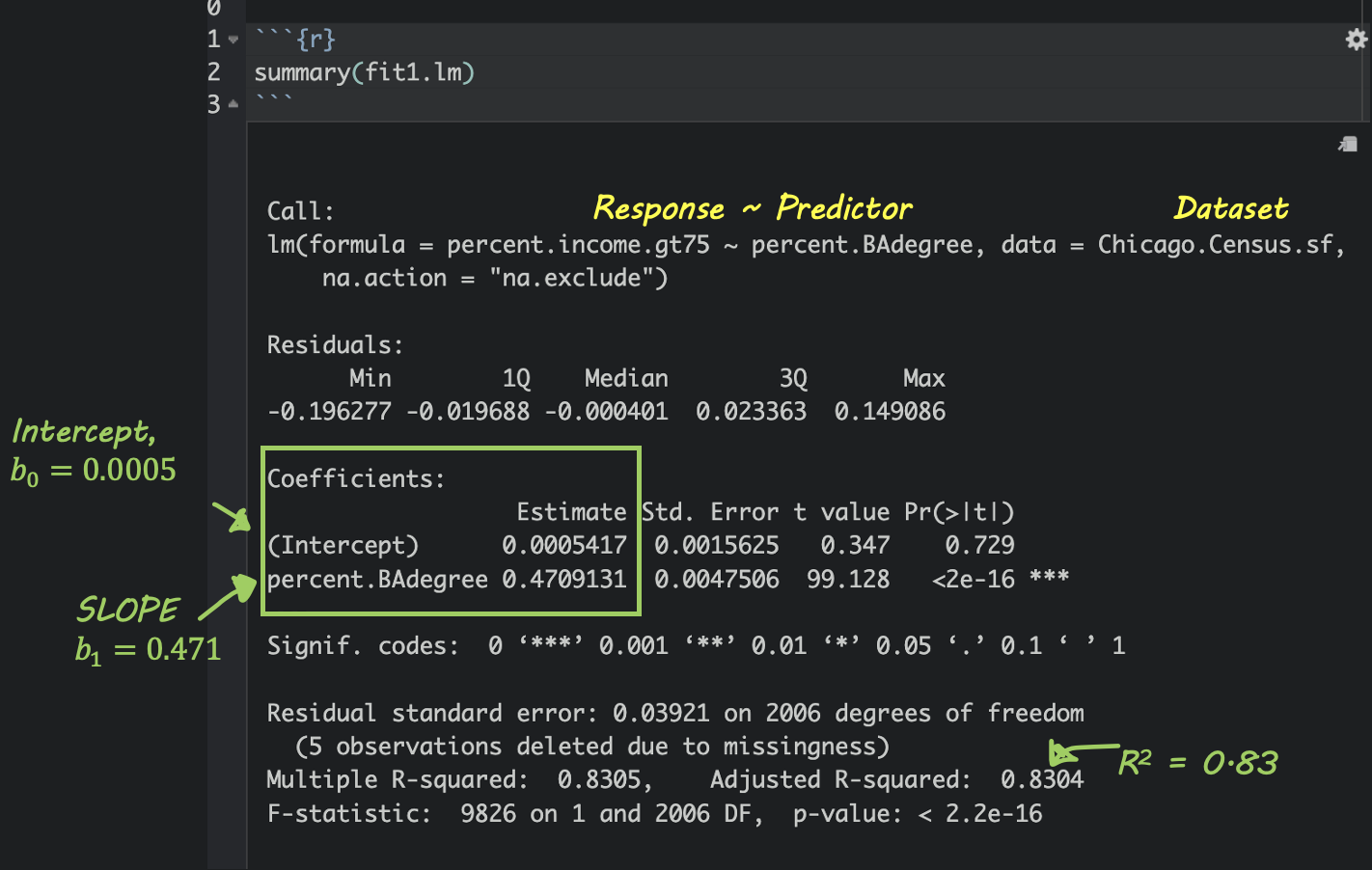
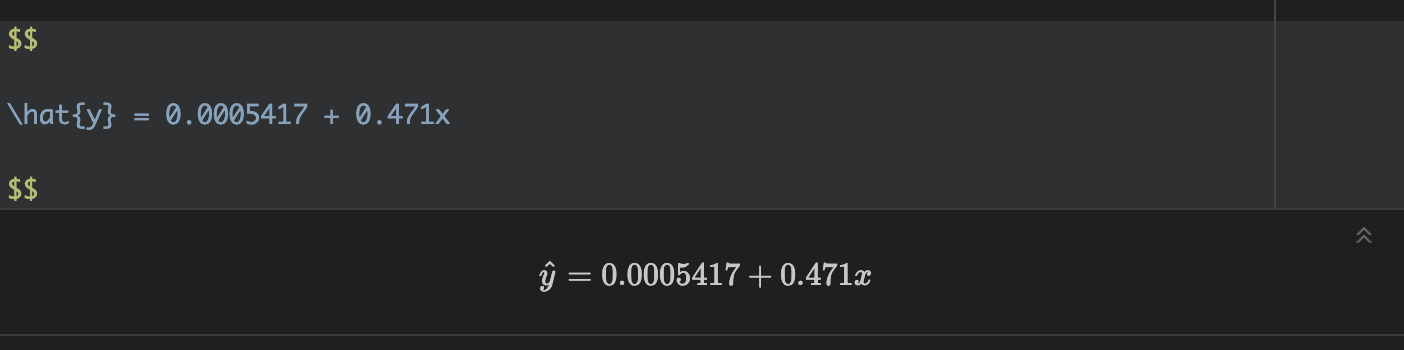
Write out the equation
You can use these numbers to write out your model equation. R understands latex equations using double dollar signs. So IN THE TEXT PART OF YOUR REPORT, try these but adjust the numbers for your model and explain what your symbols mean. I’m purposefully not writing what they are here (see the Theory Refresh section above!).
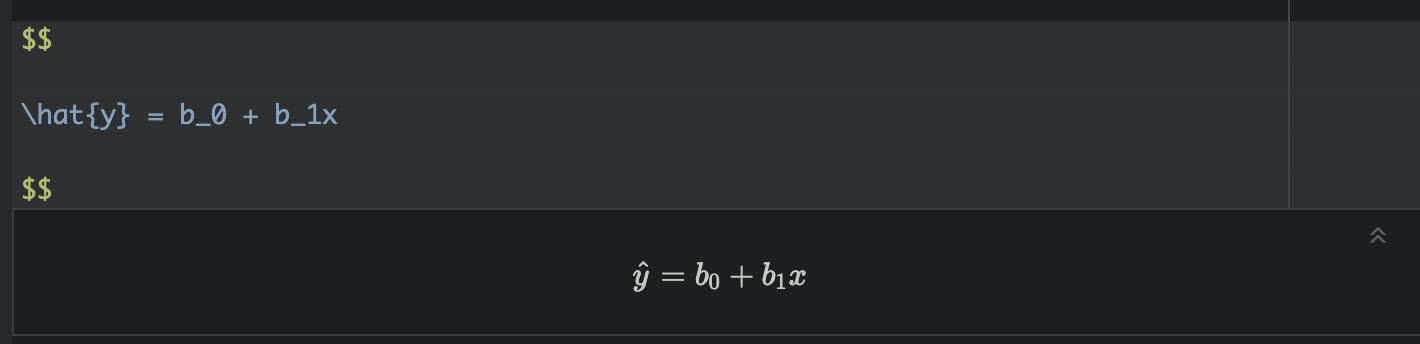
or
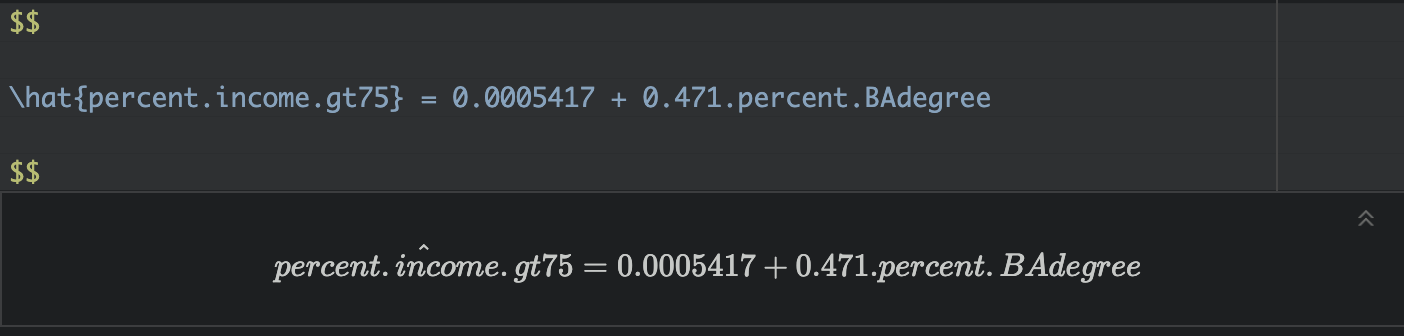
Where both are unitless percentages.
Interpret the equation
So in my case,
Intercept For census tracts where ZERO ppl have a degree, we expect only about 0.00054% of people to make over $75K. (these census tracts exist, see the plot)
Slope/gradient. For each percentage increase in people with a degree, we expect the percentage of people making over $75K to increase by 0.47%.
Update the plot
# Make an interactive plot
p <- Chicago.Census.sf %>%
ggplot(aes(
x = percent.BAdegree,
y = percent.income.gt75
)) +
geom_point(aes(label = NAME), size = 1, alpha = 0.5) +
geom_smooth(method = lm, se = FALSE) + # NEW LINE OF BEST FIT
labs(
x = "% households per tract with degree",
y = "% households per tract with income > $75k USD"
) +
theme_bw(base_size = 10)
ggplotly(p)STEP 3. Mapping model 1
Mapping the results
Add model output to our data
So we have a model! The scatterplot looks pretty good, but given that each object is an individual census tract, we can also make some maps. The easiest way to do this is to add the model forecast values to our data.frame.
Chicago.Census.sf$fit1_predict <- predict(fit1.lm)
Chicago.Census.sf$fit1_residual <- residuals(fit1.lm)Mapping the results
So we have a model! The scatterplot looks pretty good, but given that each object is an individual census tract, we can also make some maps.
These maps can show the actual values of x and y, the predicted values of x and y and the difference between them (the residuals).
For these maps, I’m switching tmap mode to plot to save computer power, but switch it back to view any time to see the interactive maps.
map_actual_y <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "percent.income.gt75",
lwd = 0,
fill.scale = tm_scale_intervals(values = "viridis",style="jenks")) +
tm_shape(st_geometry(Chicago.city.sf), unit = "km") +
tm_borders()+
tm_title("ACTUAL % ppl per tract making > $75K", size = 0.95) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
map_predicted_y <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "fit1_predict",
lwd = 0,
fill.scale = tm_scale_intervals(values = "viridis",style="jenks")) +
tm_shape(st_geometry(Chicago.city.sf), unit = "km") +
tm_borders()+
tm_title("MODEL1 prediction: % ppl per tract making > $75K", size = 0.95) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
map_residuals <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "fit1_residual",
lwd = 0,
fill.scale = tm_scale_intervals(values = "brewer.prgn",midpoint=0)) +
tm_shape(st_geometry(Chicago.city.sf), unit = "km") +
tm_borders()+
tm_title("MODEL1 RESIDUALS (difference between actual and prediction)", size = 0.95) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
suppressMessages(tmap_arrange(map_actual_y,map_predicted_y,map_residuals))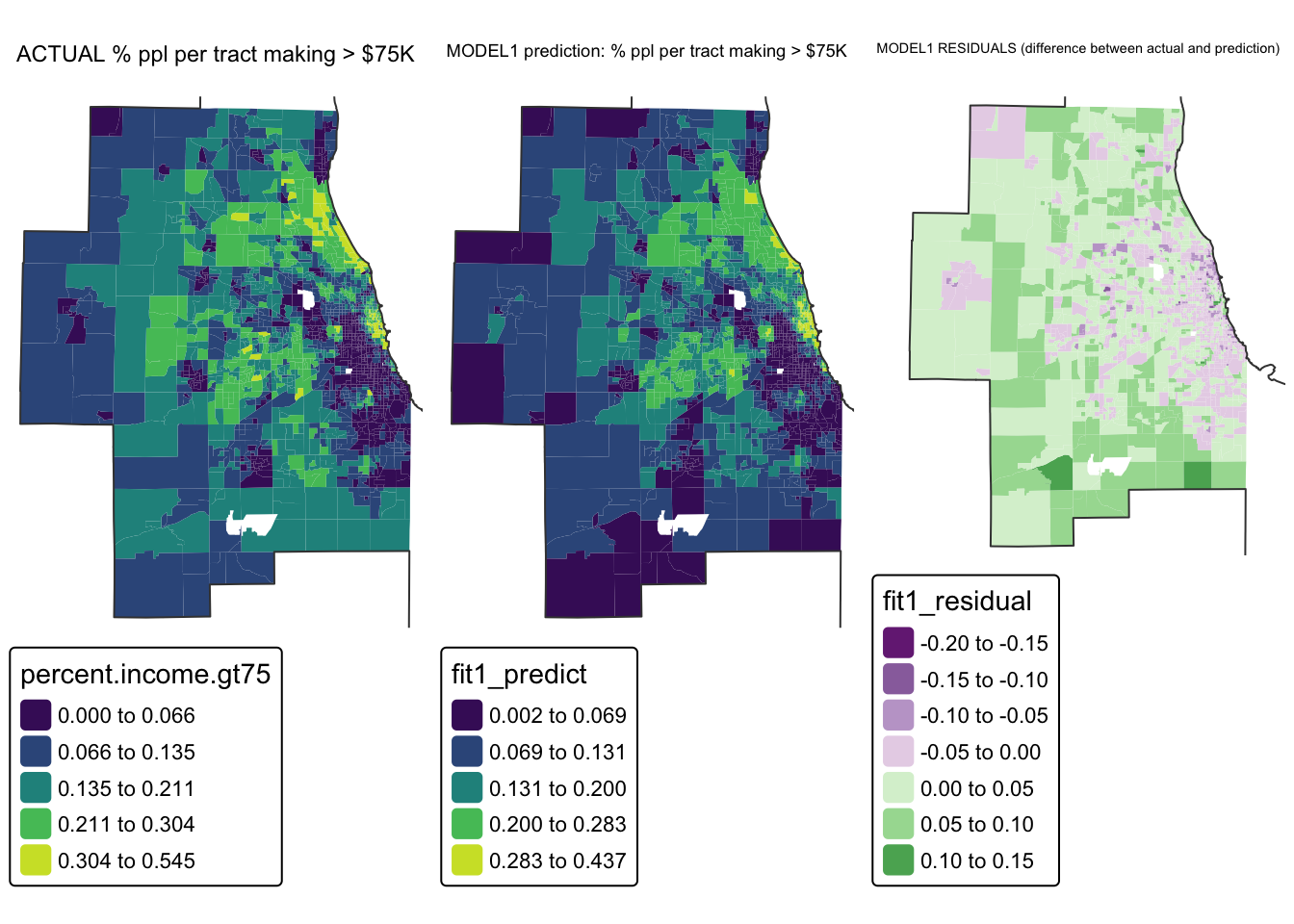
So here we can see that the model is doing a reasonable job - the residuals are within 0.2 to +0.2 (e.g. we’re overestimating the % people making >$75K in the purple areas by around 0.2% and underestimating by about the same in the green areas.
STEP 4 Spatial autocorrelation in residuals
One of the 4 assumptions around regression is that your data should be independent.
If that is true then our residuals (what is left over) should not have any influence or knowledge of each other - so their pattern in space should look like complete spatial randomness. The map above looks reasonable, but what if our color scale is skewing things.
Let’s look for any extreme residuals by converting to standard deviations/z-scores.
# Add in standardised residuals
Chicago.Census.sf$fit1_resid_ZScore <- scale(Chicago.Census.sf$fit1_residual)[,1]
tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "fit1_resid_ZScore",
lwd = 0,
fill.scale = tm_scale_intervals(values = "brewer.rd_bu",
midpoint=0, style="fixed",
breaks = c(-14,-3,-1,1,3,14))) +
tm_shape(st_geometry(Chicago.city.sf), unit = "km") +
tm_borders()+
tm_title("Fit1 Residuals - units = standard deviations from 0", size = 0.7) +
tm_layout(
legend.outside = TRUE,
legend.title.size = 0.8,
frame = FALSE )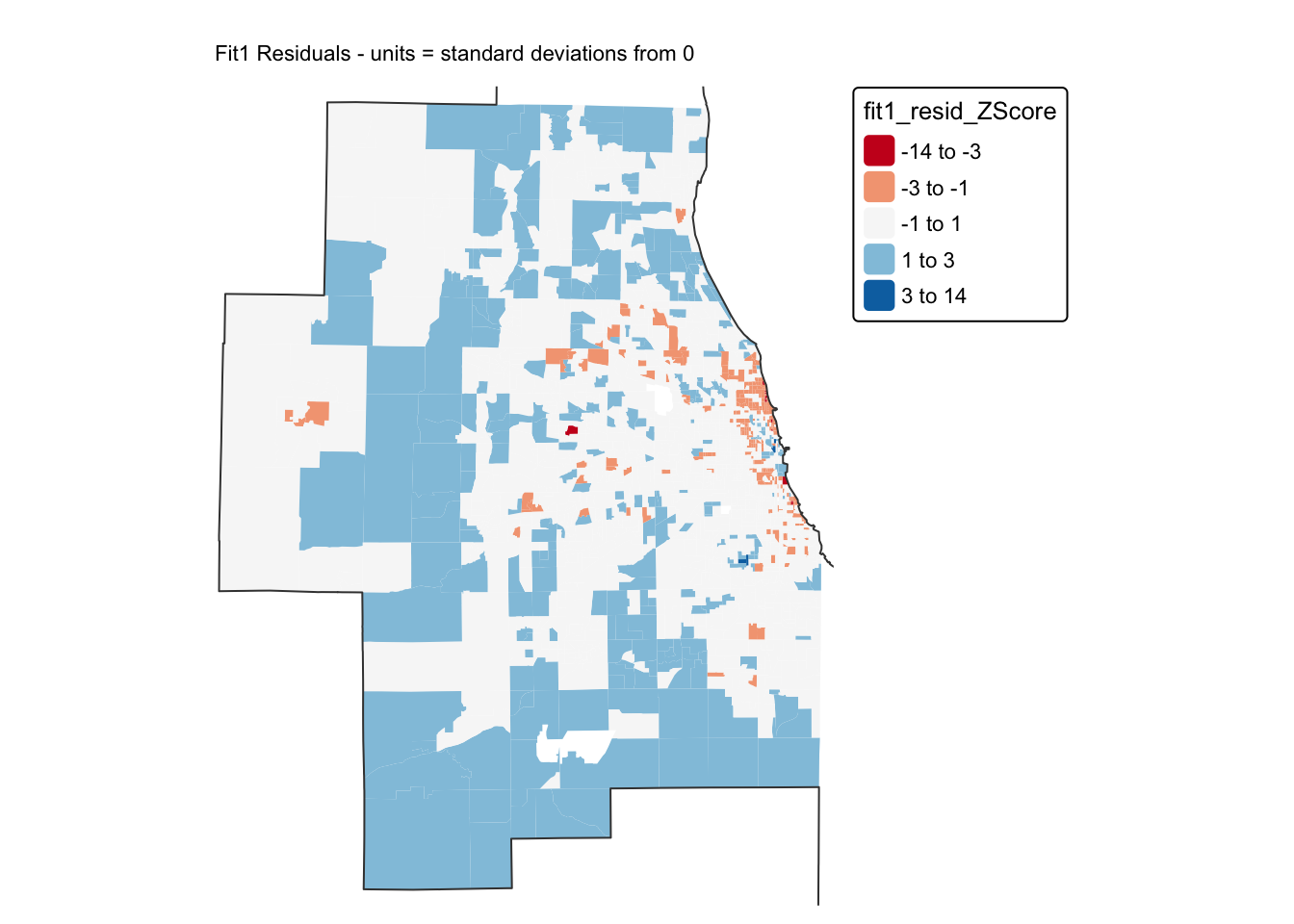
A good model should have very few residuals that are more than 2 standard deviations from zero and no patterns. I can only see a few residuals > 2, but I DEFINITELY think I see a spatial pattern in these residuals…
To see if we are “seeing pictures in clouds” or there really is a spatial pattern, we can look at a Moran’s scatterplot with a queen’s spatial matrix.
Get spatial weights (you should already have these)
Now you should already have neighbours and spatial weights matrices calculated from earlier in the lab. Look in your environment tab for something like “neighbor.queens”. If so, you don’t need this code and can move to the Moran’s plots.
Just in case, here’s the code.
# remove missing data
Chicago.Census.sf <- Chicago.Census.sf %>%
st_transform(26916) %>%
filter(!st_is_empty(geometry)) %>%
filter(pop.density_km2 > 0) %>%
st_make_valid()
# Get the geometry/coords and queens neighbours
Chicago.tract.geometry <- st_geometry(Chicago.Census.sf)
neighbor.queens <- st_contiguity(Chicago.tract.geometry, queen=TRUE)
weights.queens <- st_weights(neighbor.queens)
# calculate the sp version of weights
weights.queens.sp <- spdep::nb2listw(neighbor.queens)Calculate Moran’s I and LISA
First, lets have a look at the Moran’s scatterplot.
# and plot , the first line adjusts the margins to make it neater.
par(mar=c(5,6,1,1))
moran.plot(Chicago.Census.sf$fit1_residual,
weights.queens.sp,
xlab = "Model 1 residuals",
ylab = "Neighbors mean residual (Queens 1st)",
labels=NULL,
cex=.8, col=rgb(0,0,0,.5),
zero.policy = T)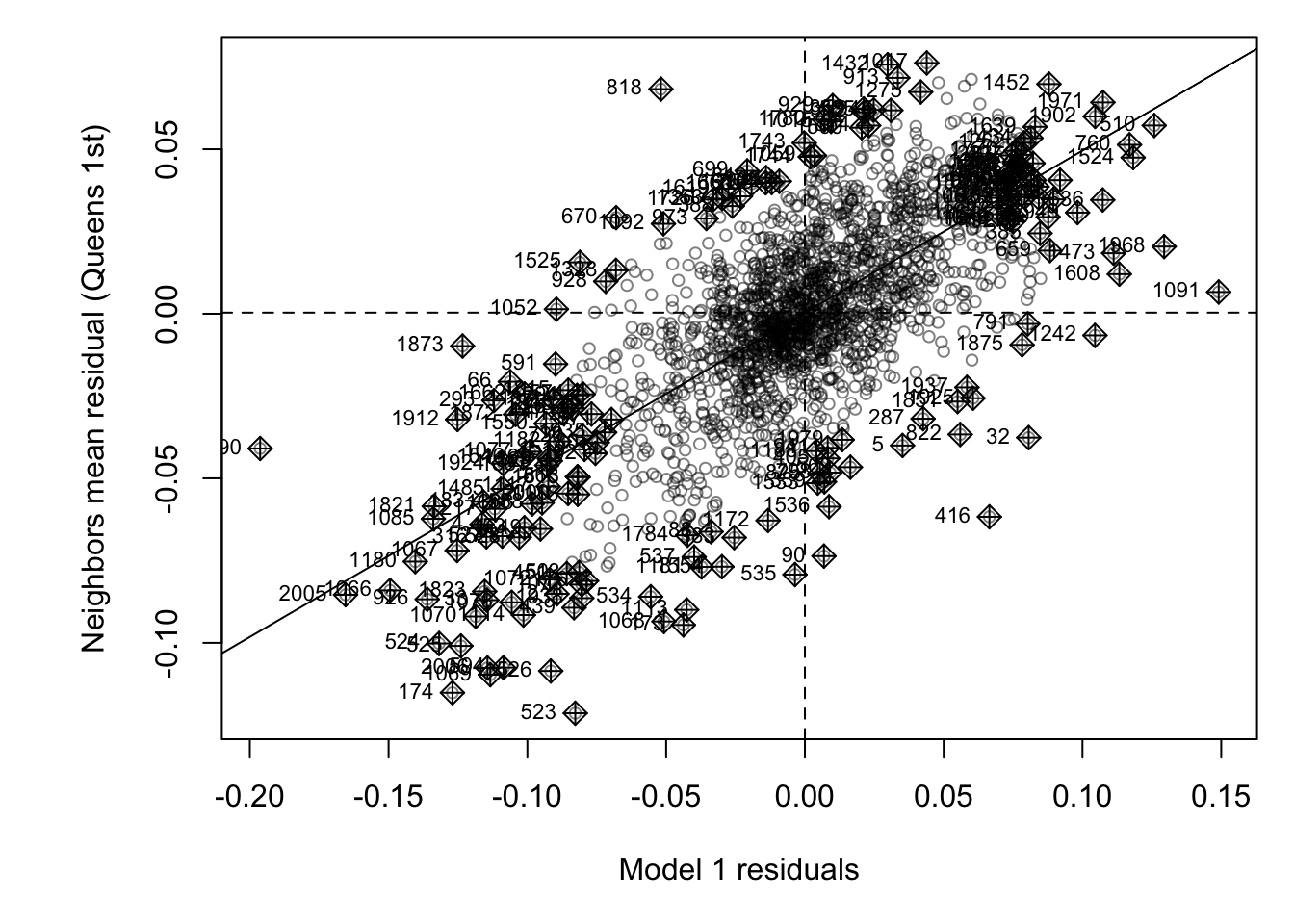
This looks like the residuals are meaningfuly clustered - e.g. a strong positive slope. To check, lets run a hypothesis test:
moran.test(Chicago.Census.sf$fit1_residual,
weights.queens.sp ,
alternative="two.sided",
zero.policy = T) ##
## Moran I test under randomisation
##
## data: Chicago.Census.sf$fit1_residual
## weights: weights.queens.sp
##
## Moran I statistic standard deviate = 39.252, p-value < 2.2e-16
## alternative hypothesis: two.sided
## sample estimates:
## Moran I statistic Expectation Variance
## 0.4927559518 -0.0004982561 0.0001579148H0: The residuals are spatially independent and show complete spatial randomness (e.g. the pattern may as well have been caused by an IRP) I=0.
H1: Global Moran’s I for the residuals is unusually High OR low compared to what we expect from spatial randomness (I != 0)
Expected Moran’s I if H0 is true = -0.0004
Actual observed Moran’s I = 0.493
Probability of seeing this if H0 was true = Tiny (less than 2.2x10-16)
From this I feel there is enough evidence to reject H0 and say that we think that the pattern is not spatially independent.
We can also dig in further using LISA. I think in here all you need to check/change is the name of Chicago.Census.sf, the name of the fit1_residual column and your neighbours variables. Oh and the plot title, but the rest should just run.
## Calculate Local moran's I
LocalMoran <- local_moran(Chicago.Census.sf$fit1_residual,
neighbor.queens,
weights.queens,
alternative = "two.sided")
Chicago.Census.sf$LISA_Resid <- LocalMoran$ii
Chicago.Census.sf$LISA_Resid_pvalue <- LocalMoran$p_folded_sim
Chicago.Census.sf$LISA_Resid_Quadrant <- factor(LocalMoran$pysal,
levels= c("High-High","High-Low",
"Low-High","Low-Low"))
Chicago.Census.sf <- Chicago.Census.sf %>%
mutate(
LISA_Resid_p.LT.05 = LISA_Resid_pvalue <= 0.05,
LISA_Resid_Quadrant_sig = as.character(LISA_Resid_Quadrant),
LISA_Resid_Quadrant_sig = if_else(LISA_Resid_pvalue > 0.05,
"p>0.05",
LISA_Resid_Quadrant_sig),
LISA_Resid_Quadrant_sig = factor(
LISA_Resid_Quadrant_sig,
levels = c("High-High", "High-Low",
"Low-High", "Low-Low", "p>0.05")
)
)
#---------------------------------------------------
tmap_mode("view")
tm_shape(Chicago.Census.sf) +
tm_polygons(
fill = "LISA_Resid_Quadrant_sig",
lwd = 0.5,
id = "NAME",
fill_alpha = 0.4,
fill.scale = tm_scale_categorical(
values = c("#ca0020",
"#f4a582",
"#92c5de",
"#0571b0",
"white"))) +
tm_legend(text.size = 1) +
tm_title("LISA: Model residual. (p<0.05)") +
tm_layout(frame = FALSE)And interpret
So in this case “Low” means the model underestimated the true number of ppl making more than $75K - there are more rich people than we expect given the education levels
And “high” (red areas) means the model overestimated the true number of ppl making more than $75K. There are less than we expect given the education levels
I will let you interpret this, but some hints as you zoom around the map.
- Why do you think the outer census tracts are mostly red?
- Why do you think most of the census tracts north of chicago city centre are blue (uptown)
- Why might I expect High-High or High-Low around universities?
Overall this is a reasonable model. In future labs and classes we will try to improve it.