TUTORIAL Local Spatial Autocorrelation
In this tutorial, I will to assess the relationship between the number of people who earn over $75000 dollars and population density in Chicago. We will practice two new techniques, LISA (local auto-regression) to see if each variable is auto-correlated with itself, then actual regression - to understand the relationship between the two.
WORK THROUGH THIS TUTORIAL, then the actual lab uses a different dataset.
STEP 1 Getting the data
Libraries needed for this tutorial.
Make sure all of these libraries are at the top of your lab script in a code chunk, and run the code chunk! If you run the code chunk and it says a package is missing, either click “install” if the little yellow bar appears at the top, or go to the Packages tab, and click Install to go to the package ‘app store’.
Remember to set the code chunk options to message=FALSE and
warning=FALSE!
E.g. switch to Source mode and make the top of the
code chunk to {r,message=FALSE, warning=FALSE}
library(corrplot)
library(ggplot2)
library(ggthemes)
library(kableExtra)
library(olsrr)
library(plotly)
library(raster)
library(RColorBrewer)
library(readxl)
library(rnaturalearth)
library(rmapshaper)
library(sf)
library(sp)
library(skimr)
library(spatialreg)
library(spatialEco)
library(spatstat)
library(spdep)
library(sfdep)
library(terra)
library(tidyverse)
library(tidycensus)
library(tigris)
library(tmap)
library(units)
library(viridis)
library(VIM)
library(dplyr)Run the code chunk a few times and check there are no errors.
Download the example data for Chicago.
First, I downloaded American Community Survey data for Illinois at a census tract spatial scale. A census tract is similar to a zip code, a much finer spatial scale than a county. The way to do this is similar to Lab 5.
Code to load the example data
We can load your data from the census and tidy up, before plotting
FOR THIS CODE CHUNK, set results=‘hide’ as a codechunk option, or it will swamp your knit: {r, results=‘hide’}
# THIS WILL NOT WORK IF YOU DIDN'T RUN YOUR API KEY CODE & RESTART R-STUDIO LAST LAB
# Download Illinois ACS data at census tract level for my chosen variables, using tidycensus
IL.Census.sf <- get_acs(geography = "tract",
year = 2017,
variables = c(total_pop = "B05012_001", # total population
income.gt75 = "B06010_011"), # number of people making > 75000 USD
state = "IL",
survey = "acs5",
geometry = TRUE,
output="wide",
cache_table = TRUE)We also need to change the map projection. As we’re focusing on a single city, lets us a local UTM projection, with EPSG code 26916. To find one for your area, see
There’s also a great tutorial here on choosing the best one https://source.opennews.org/articles/choosing-right-map-projection/
# Change the map projection to Albers equal projection,
# then remove empty polygons (lakes etc) and fix any broken geometry
IL.Census.sf <- IL.Census.sf %>%
st_transform(26916) %>%
st_make_valid()You can see the data summarized here. Each column ending in E means the estimate of the value in each census tract and the column ending in M means the margin of error.
For more advanced work we probably want to keep the error columns. But here let’s remove them.
# Remove and rename error columns
IL.Census.sf <- IL.Census.sf %>%
dplyr::select(
GEOID,
NAME,
total_pop = total_popE,
income.gt75 = income.gt75E,
geometry )Rather than looking at the total population, it makes sense to scale by the size of each tract, so that bigger tracts don’t skew our results. We want:
- the population density (e.g. total_pop / Area)
- the percentage of people earning over $75K (e.g. income.gt75 /
total_pop)
# Find the areas in each county & change the units from metres squared to km squared
IL.Census.sf$Area <- st_area(IL.Census.sf)
IL.Census.sf$Area <- as.numeric(set_units(IL.Census.sf$Area,"km^2"))
# Divide the total population & housing by the area to give the population/housing density
IL.Census.sf$pop.density_km2 <- IL.Census.sf$total_pop / IL.Census.sf$Area
# Divide the total population & housing by the area to give the population/housing density
IL.Census.sf$percent.income.gt75 <- IL.Census.sf$income.gt75 / IL.Census.sf$total_popHere is the summary of the data I downloaded with the new columns added in. You can see that there are 3123 census tracts in Illinois and that the data is clearly marked, with 8 columns of data.
Data wrangling
Dealing with empty polygons
One quirk of R is that it **hates* empty polygons so it’s good to check for them. IF YOU GET ERRORS PLOTTING, I BET THIS IS WHAT IS HAPPENING.
In our case, empty polygons means empty census tracts. These might be census tracts where no-one lives, or more likely, a quirk of the data collection process. Let’s take a look at them.
We can check this with the st_is_empty() command:
OK so it’s tracts 9900 in Cook county and lake county Illinois. Let’s google that… and the results suddenly make sense!
It’s the lake! I feel satisfied that removing these polygons won’t mess up my study. So I’m going to go ahead and remove them and overwrite the results. E.g. I apply the filter command to IL.Census.sf, asking it to only choose rows where which_tracts_empty is FALSE, then save the result to IL.Census.sf.
Now.. let’s try again. Yep, we have removed the empty fields.
Quick check
I then had a quick look at the data in tmap to make sure it looked good, using the code from previous labs.
# create map 1
map1 <- tm_shape(IL.Census.sf, unit = "km") +
tm_polygons(
fill = "income.gt75",
lwd = 0,
fill.scale = tm_scale_intervals(
style = "pretty",
values = "brewer.yl_gn_bu",
)
) +
tm_title("Number of people making $75K per census tract", size = 0.75) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
map2 <- tm_shape(IL.Census.sf, unit = "km") +
tm_polygons(
fill = "percent.income.gt75",
lwd = 0,
fill.scale = tm_scale_intervals(
style = "quantile",
values = "brewer.reds",
)
) +
tm_scalebar(breaks = c(0, 10, 20)) +
tm_compass(type = "4star", position = c("left", "bottom")) +
tm_title("Percentage of people making $75K per census tract", size = 0.75) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
tmap_mode("plot")
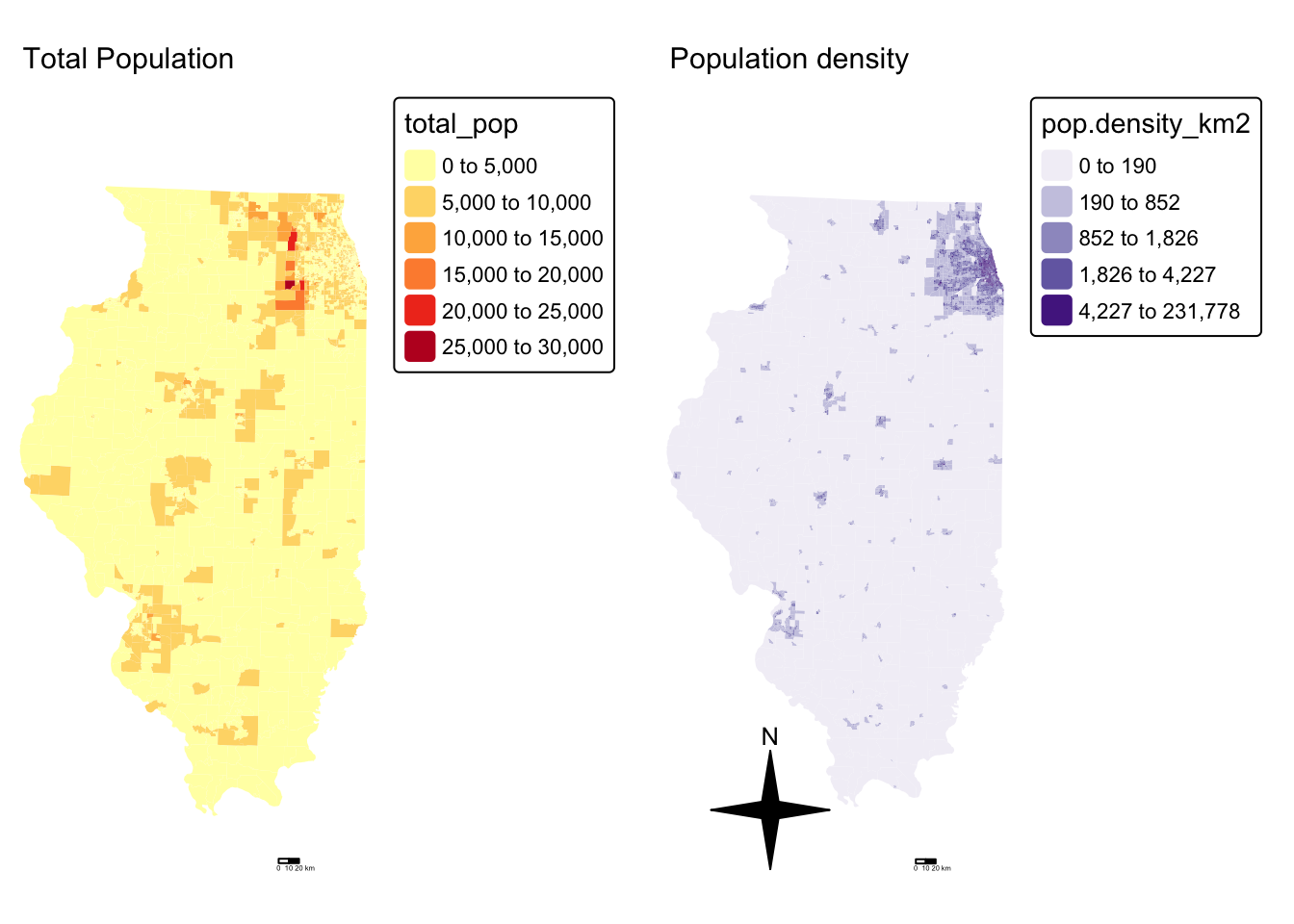
suppressMessages(tmap_arrange(map1,map2))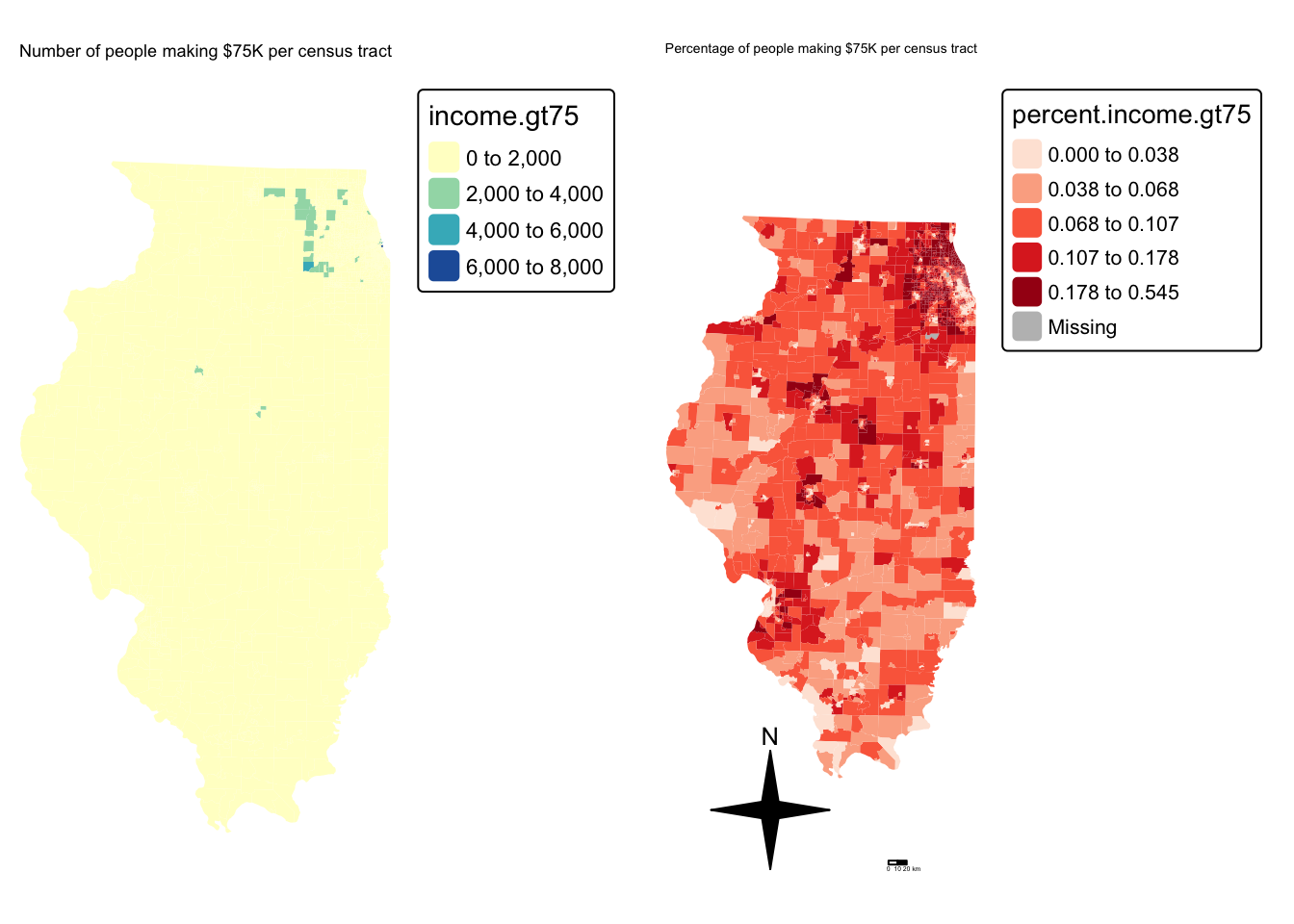
and population density
Cropping to Chicago
This map looks at all of Illinois. But we want to look at the area just around Chicago. Let’s crop to the city’s administrative boundaries. We can download these using the Tigris package.
Tigris has thousands of boundary data-sets that you can explore. For a tutorial, see here [https://crd150.github.io/lab4.html#tigris_package] and here [https://github.com/walkerke/tigris]
For now, lets download the Chicago metropolitan area data then select Chicago
FOR THIS CODE CHUNK, set results=‘hide’ as a codechunk option, or it
will swamp your knit:
{r, results='hide'}
cb.sf <- core_based_statistical_areas(cb = TRUE, year=2017)
Chicago.city.sf <- filter(cb.sf, grepl("Chicago", NAME))
# and set the projection to be identical to the census data
Chicago.city.sf <- Chicago.city.sf %>%
st_transform(26916) %>%
st_make_valid()and, just so you can see what I have done..
We can now crop our census data to this specific area using the
ms_clip function.
# subset the Illinois census data with the Chicago city limits
Chicago.Census.sf <- ms_clip(target = IL.Census.sf,
clip = Chicago.city.sf,
remove_slivers = TRUE)Let’s remake that map, remember to play with the style option if your color scale isn’t useful
# create map 1
tmap_mode("plot")
map2 <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "percent.income.gt75",
lwd = 0,
fill.scale = tm_scale_intervals(
style = "quantile",
values = "brewer.reds",
)
) +
tm_shape(st_geometry(Chicago.city.sf), unit = "km") +
tm_borders()+
tm_scalebar(breaks = c(0, 10, 20)) +
tm_compass(type = "4star", position = c("left", "bottom")) +
tm_title("Percentage of people making $75K per census tract", size = 0.75) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
#and
map4 <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "pop.density_km2",
lwd = 0,
fill.scale = tm_scale_intervals(
style = "quantile",
values = "brewer.purples",
)) +
tm_shape(st_geometry(Chicago.city.sf), unit = "km") +
tm_borders()+
tm_scalebar(breaks = c(0, 10, 20)) +
tm_compass(type = "4star", position = c("left", "bottom")) +
tm_title("Population density", size = 0.95) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
# and print
suppressMessages(tmap_arrange(map2,map4))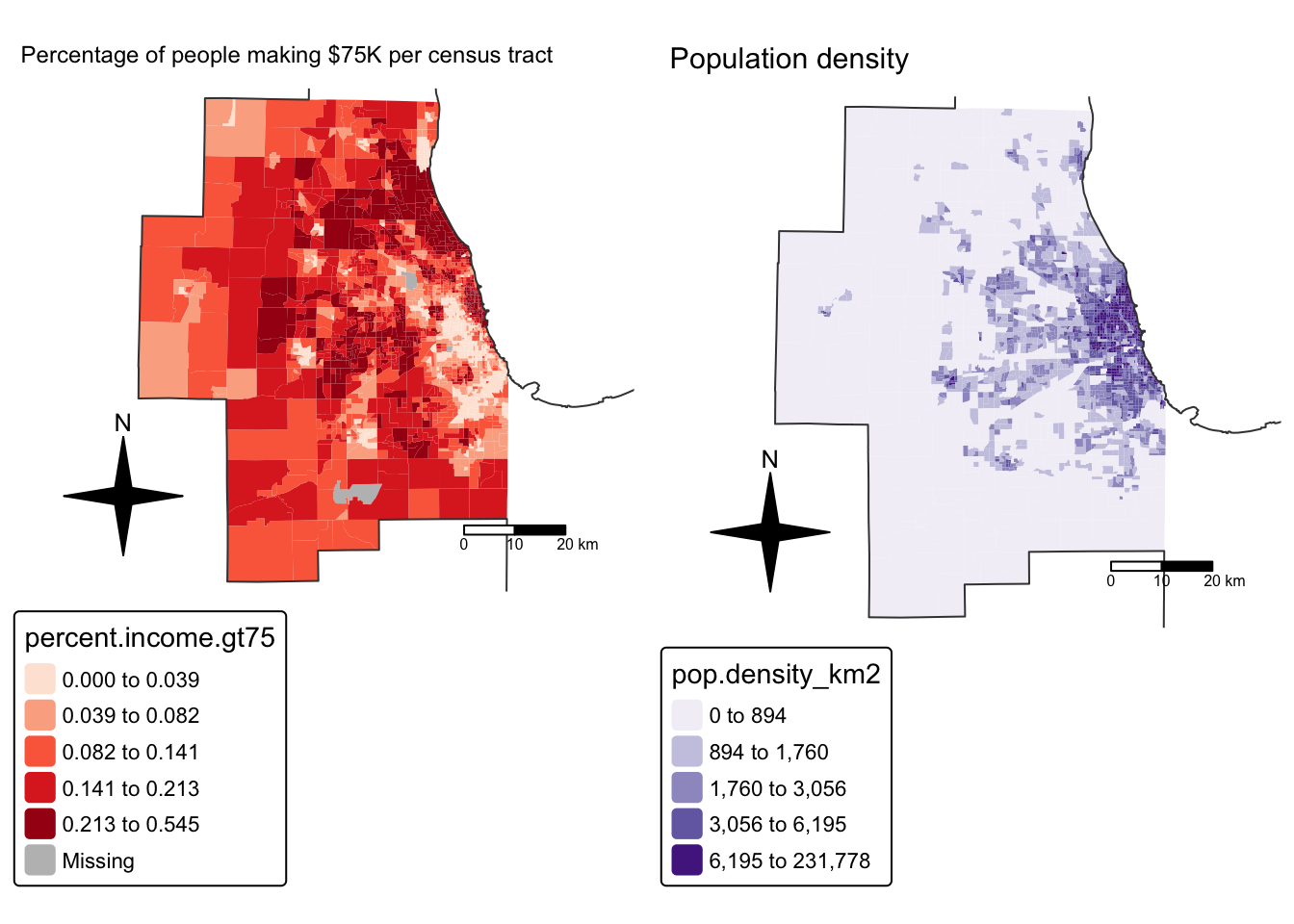
STEP 2 Global Autocorrelation
Here we are going to look BOTH at global Moran’s I and its local equivalent, LISA. Because it builds directly on your previous lab, I’m going to refer to the tutorial but hide my code.
Dealing with issues
It turns out that subsetting to the city borders put our empty lake tracts back in! Let’s remove and tidy
Spatial weights
This tutorial shows you how to calculate a spatial weights matrix for your data. https://psu-spatial.github.io/Geog364-2025/Tutorial_SpatWeights.html.
Remember to change the variable from ACS_country.geometry to whatever you are using. I am using Chicago.city.sf.
Using the tutorial, I calculated a QUEENS 1ST ORDER weights matrix
Because I had so many polygons, here’s how I plotted them:
# And plot
par(mar=c(1,1,1,1))# big plot area
plot(Chicago.city.geometry,
border='darkcyan',
lwd=.5)
plot(neighbor.queens, st_coordinates(Chicago_county.centroid),
col=rgb(0,0,0,.4), # transparent black
lwd=.5, # thin lines
pch=16, cex=.1, # tiny dots
add=TRUE)
Moran’s I rerun
I’m now going to see if one of my variables is auto-correlated - the percentage of people earning over $75K.
To do this, I used the code in https://psu-spatial.github.io/Geog364-2025/Tutorial_Moran.html adjusting for my location and my variable name (percent.income.gt75)
## [1] "GEOID" "income.gt75" "NAME"
## [4] "total_pop" "Area" "pop.density_km2"
## [7] "percent.income.gt75" "geometry"But I get an error! (note this is old code USE THE CODE IN THE TUTORIAL) It says I have missing values in “x” AKA in my percentage income column.

There are missing values in your column of choice
Let me check:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00000 0.04773 0.11132 0.12894 0.19147 0.54485Yes - three polygons didn’t calculate properly. Let’s take a look:
It turns out there are OTHER census tracts which don’t have data (or zero population). lets remove those and try again. I’m going to remove ones with zero population density. Which means I need to recreate my spatial weights matrix…
# remove missing data
Chicago.Census.sf <- Chicago.Census.sf[Chicago.Census.sf$pop.density_km2 > 0 , ]
# recalculate spatial weight
Chicago.city.geometry <- st_geometry(Chicago.Census.sf)
neighbor.queens <- st_contiguity(Chicago.city.geometry, queen=TRUE)
weights.queens <- st_weights(neighbor.queens)Now, my moran’s plot works. As we have a lot of data, I also adjusted the plotting to make the points smaller. This allows us to clearly see any outliers.
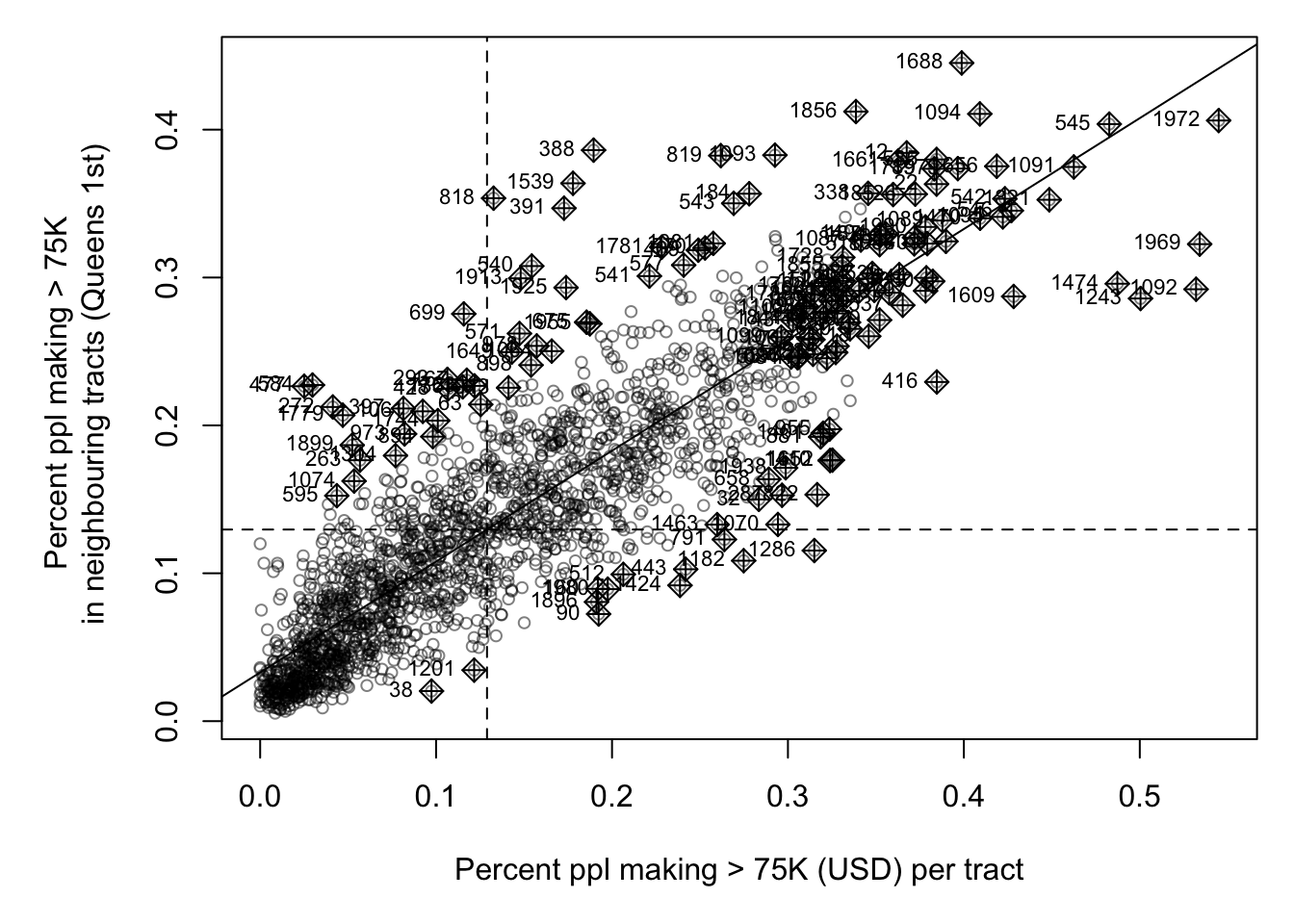
It looks very clustered.. (which agrees with the map I made). Let’s do a test. I’ll let you interpret it based on your lecture notes (and see the most recent discussion)
##
## Moran I test under randomisation
##
## data: Chicago.Census.sf$percent.income.gt75
## weights: weights.queens.sp
##
## Moran I statistic standard deviate = 59.684, p-value < 2.2e-16
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.7497117818 -0.0004980080 0.0001579947STEP 3 Local Autocorrelation (LISA)
Moran’s I is just a global statistic, so it would be useful to know where the data is clustered or not and if that clustering is significant.
Calculating the lisa statistic
We do this by calcualting Local moran’s I. We will discuss in class, but essentially we calculate Moran’s I for just each polygon with its neighbours
LocalMoran <- local_moran(Chicago.Census.sf$percent.income.gt75,
neighbor.queens,
weights.queens,
alternative = "two.sided")
head(LocalMoran)Here’s what the results mean. They calculate significance based on the monte carlo approach we discussed in class:
iiLocal moran statistic e.g. Moran’s I for each census tract (i)eiiExpected value of local moran statistic;var_iivariance of local moran statistic;z_iiZ score of the local moran statistic;p_iip-value of local moran statistic for that census tractp_ii_simSim p-value using our Monte Carlo approach for H1 alternative=“two.sided”p_folded_simThe simulation folded [0, 0.5] range ranked p-value (based on https://github.com/pysal/esda/blob/4a63e0b5df1e754b17b5f1205b8cadcbecc5e061/esda/crand.py#L211-L213)skewnessthe output of e1071::skewness()kurtosisthe output of e1071::kurtosis()meanthe average quadrant of the moran’s scattrplot for each census tract (out of the monte carlo)medianthe median quadrant of the moran’s scattrplot for each census tract (out of the monte carlo)pysalthe pysal average quadrant of the moran’s scattrplot for each census tract (out of the monte carlo)
We can simplify this given that we’re in an undergrad class! We can also add it to our census data:
Chicago.Census.sf$LocalMoran <- LocalMoran$ii
Chicago.Census.sf$LocalMoran_pvalue <- LocalMoran$p_folded_sim
Chicago.Census.sf$Quadrant <- factor(LocalMoran$pysal,
levels= c("High-High","High-Low",
"Low-High","Low-Low"))
Chicago.Census.sfWe can now see how many points fell into each quadrant
##
## High-High High-Low Low-High Low-Low
## 769 106 158 976Plotting
We can now make our first LISA plot!
#---------------------------------------------------
# And make a map, remember you can switch to "plot" mode
# if your computer struggles
#---------------------------------------------------
tmap_mode("view")
mapLISA <- tm_shape(Chicago.Census.sf) +
tm_polygons(
fill = "Quadrant",
fill_alpha = 0.6,
lwd = 0,
id = "NAME",
col_alpha = 0.5,
fill.scale = tm_scale_categorical(
values = c("#ca0020",
"#f4a582",
"#92c5de",
"#0571b0"))) +
tm_legend(text.size = 1) +
tm_title("LISA: % earning > $75K") +
tm_layout(frame = FALSE)
# Compare against the original data
map2 <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "percent.income.gt75",
lwd = 0,
fill.scale = tm_scale_intervals(
style = "quantile",
values = "brewer.yl_gn_bu",
)
) +
tm_scalebar(breaks = c(0, 10, 20)) +
tm_title("Percentage of people making $75K per census tract", size = 0.75) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
mapLISAAnd adjust for significance
There are three ways we could do this.
simply plot significance
First, we could plot the values next to the pvalues:
#---------------------------------------------------
# And make a map
#---------------------------------------------------
tmap_mode("view")
mapLISA <- tm_shape(Chicago.Census.sf) +
tm_polygons(
fill = "Quadrant",
fill_alpha = 0.6,
lwd = 0,
id = "NAME",
col_alpha = 0.5,
fill.scale = tm_scale_categorical(
values = c("#ca0020",
"#f4a582",
"#92c5de",
"#0571b0"))) +
tm_legend(text.size = 1) +
tm_title("LISA: % earning > $75K") +
tm_layout(frame = FALSE)
# Compare against the p values
mapPvalues <- tm_shape(Chicago.Census.sf, unit = "km") +
tm_polygons(
fill = "LocalMoran_pvalue",
lwd = 0,
fill.scale = tm_scale_intervals(
breaks=c(0,0.001,0.01,0.05,0.1,1),
values = rev(cols4all::c4a("brewer.greens")))) +
tm_title("P-value for each quadrant", size = 0.75) +
tm_layout(
legend.outside = TRUE,
frame = FALSE
)
suppressMessages(tmap_arrange(mapLISA,mapPvalues))Remove colors
The second is that we can set the values above some threshold to white. I chose a threshold significance of 0.05.
# get the new values. TRUE if p < 0,05
Chicago.Census.sf <- Chicago.Census.sf %>%
mutate(
p.LT.05 = LocalMoran_pvalue <= 0.05,
Quadrant_sig = as.character(Quadrant),
Quadrant_sig = if_else(LocalMoran_pvalue > 0.05,
"p>0.05", Quadrant_sig),
Quadrant_sig = factor(
Quadrant_sig,
levels = c("High-High", "High-Low",
"Low-High", "Low-Low", "p>0.05")
)
)
# and make a map
#---------------------------------------------------
tmap_mode("view")
tm_shape(Chicago.Census.sf) +
tm_polygons(
fill = "Quadrant_sig",
lwd = 0.5,
id = "NAME",
fill_alpha = 0.4,
fill.scale = tm_scale_categorical(
values = c("#ca0020",
"#f4a582",
"#92c5de",
"#0571b0",
"white"))) +
tm_legend(text.size = 1) +
tm_title("LISA: % earning > $75K if p<0.05") +
tm_layout(frame = FALSE)Here, we can see that there are many census tracts with lots of people making over $ 75K, surrounded by neighbours that make the same. Equally there are many neighbourhoods in Chicago where there are few “high earning” residents. So this shows that yes, there is absolutely clustering overall in Chicago in this variable, but this gives us some more insight into where…
It also allows us to examine outliers. For example, this low-high area
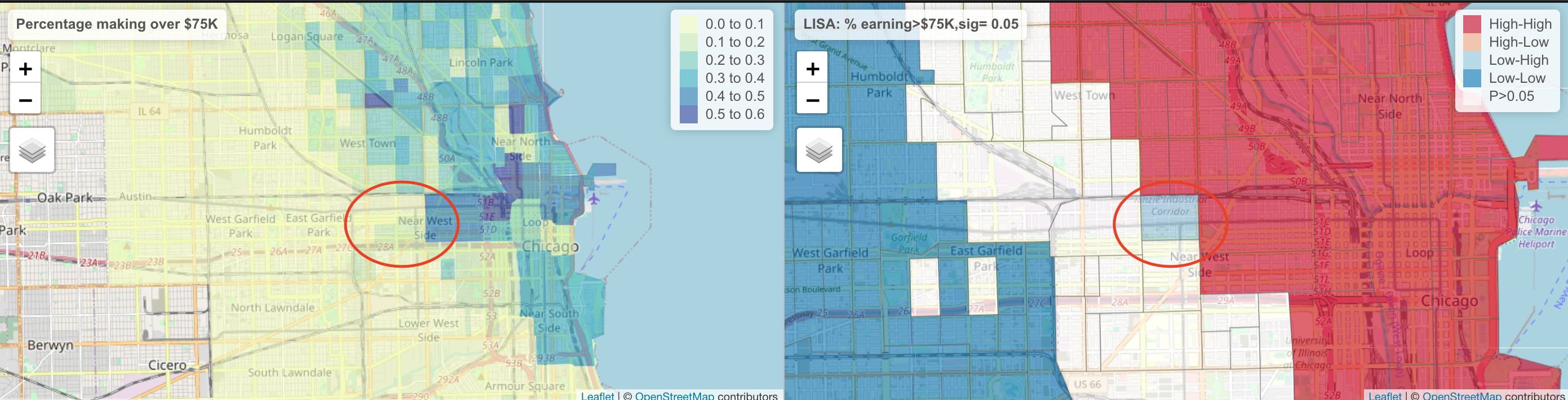
The stark difference here makes me want to explore this further for process. Maybe there is an industrial area here - maybe this is a legacy of Chicago’s massive legacy of redlining and housing discrimination (https://www.bloomberg.com/news/articles/2020-09-30/mapping-the-disparities-of-chicago-s-unequal-pandemic). Maybe there is a single luxury housing block next door. But it is definitely interesting!