Lab 4: Code showcase
STAT-462 - Regression Analysis
Dr Helen Greatrex
Learning objectives
It’s nearly spring break, so this lab is one big code showcase to get comfortable with the commands.
By the end of this week’s lab, you will be able to:
- Feel comfortable reading in and filtering data
- Feel comfortable with the core regression commands.
- Look at LINE assumptions
Assignment 4 is due by midnight before spring break. See here I PROVIDE HELP UNTIL THE END OF NEXT WEEK’S LAB. After next week’s lab (All of Wed night/Thurs/Fri) is for your own finishing up.
I need help
There is a TEAMS discussion for lab help CLICK HERE. Remember to include a screenshot of the issue and a short description of the problem. Also try googling the error first.
Every time you re-open R studio check you are using your project file (does it say Lab 4 at the top?).
EVERY TIME YOU RE-OPEN R-STUDIO YOU NEED TO RE-RUN ALL YOUR CODE CHUNKS. The easiest way to do this is to press the “Run All” button (see the Run menu at the top of your script)
If the labs are causing major problems or your computer hardware is struggling (or you have any other software issue), Talk to Dr Greatrex. We can fix this and there are other free/cheap options for using R online.
STEP1: Lab set-up. DO NOT SKIP!
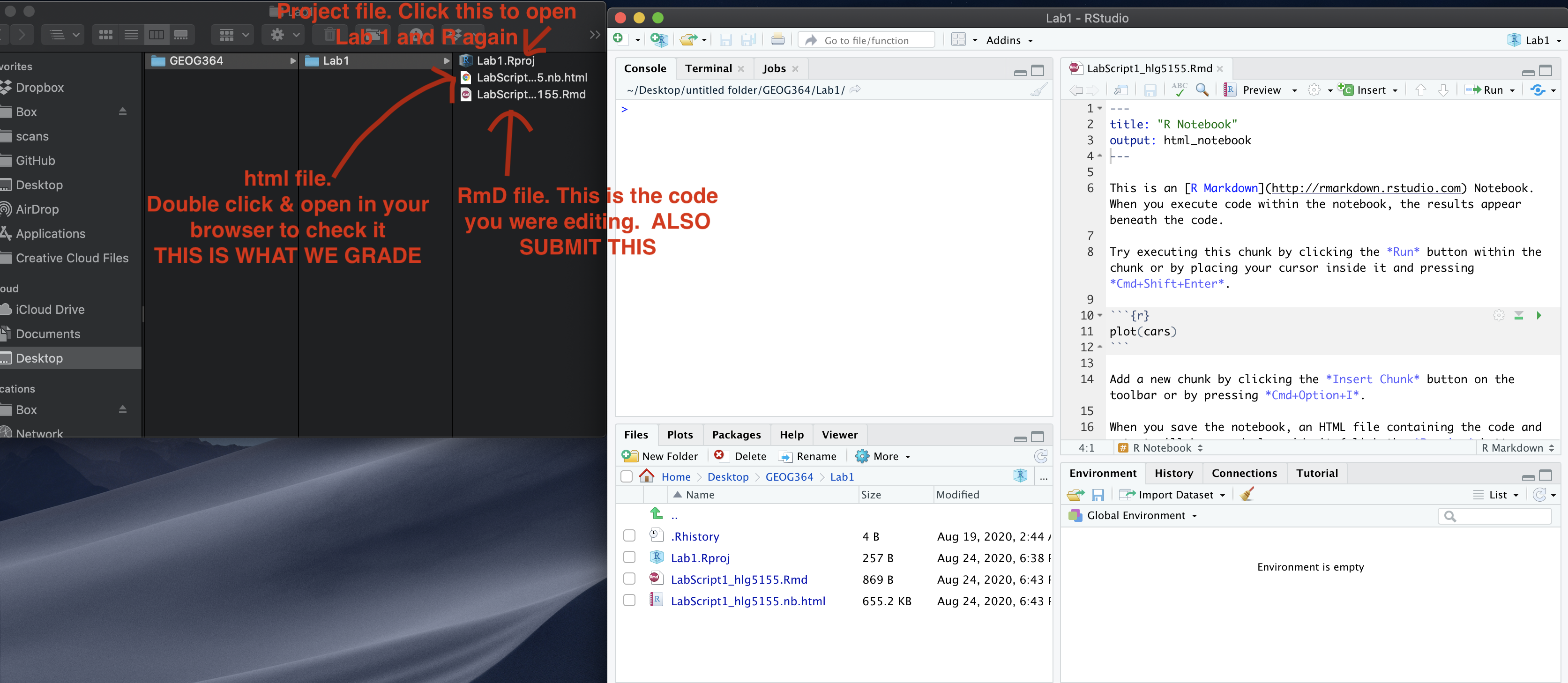
- Create a new project for Lab 4. If you are stuck, see previous labs or Tutorial 2.1.
- Copy your lab template to your lab 4 folder, rename as STAT-462_Lab4_EMAILID.Rmd (e.g.STAT-462_Lab4_hlg5155.Rmd) and open. THIS LAB IS ONE BIG CODE SHOWCASE. Delete all the headings/subheadings after Code Show case.
- In the library section, add a new code chunk and use this code to load the following libraries.
If some don’t exist on your computer or on the cloud, use Tutorial 2.3 to install/download them first.
To make sure they loaded OK, run the code chunk TWICE. The second time any welcome text will disappear unless there are errors.
library(tidyverse)
library(dplyr)
library(ggpubr)
library(GGally)
library(skimr)
library(ggplot2)
library(plotly)
library(equatiomatic)
library(olsrr)
library(Stat2Data)
library(readxl)
library(yarrr)- Finally, press knit to check the html works and it looks like this (with your theme)
STEP 2: Code showcase
This lab is a series of mini challenges. For each challenge, please add a new sub-heading to make it easy to grade.
You might want to make a second .Rmd file to practice the tutorials, so you can save your practice but only write up what is needed in your report
You will need the code from these NEW TUTORIALS:
Challenge 1: Leaf Analysis
The aim of this question is to support you with some of the learning objectives of question 4 in the exam.
- Use the data command to load the
LeafWidthdataset(make sure you have run the library code chunk first). Look at the help file for the dataset to understand what you are looking at and what the column names mean. In the text, identify the specific unit of analysis.
You are looking at two variables: a. Year the leaves were collected b. Average length of each leaf (in mm)
For EACH of the two variables above
- Create a professional looking boxplot
- Below the boxplot, write whether you believe the variable is likely to be Normally distributed and why.
- Add a guess of a p-value in a Wilk-Shapiro test. (you are not being graded on whether your answer is ‘correct’)
- Formally assess the normality of the variable using a Wilk-Shapiro test at a critical value of 5%. Include your H0, H1 and your conclusions. Write a comment on whether the result matches your guess. (you could also have a look at a histogram).
- Create a professional looking boxplot
Is the Wilk-Shapiro test one-sided or two-sided? (google it!)
Someone adds a new leaf to the dataset. Calculate the range of lengths are you 99% sure the new leaf will have.
Someone collects a whole new sample from your population. Given your data, what is your estimate of their average leaf length, with a 95% level of certainty.
Given the Wilk-Shapiro test results above, would it have been appropriate to calculate the ranges from [4] and [5] for a variable as skewed as ‘the year the leaves were collected?’ Explain your answer. (Hint Lecture 9)
Challenge 2: Filtering Data
You might find TUTORIAL 11: Filtering/choosing/sub-setting data useful (the code is in there!).
data("pirates", package = "yarrr")
piratenew <- dplyr::filter(pirates,parrots > 3)
mean(piratenew$tattoos)## [1] 9.033962Load the
piratesdataset from theyarrrpackage. Take a look at it and the help file.Select the value of the pirates dataset for the 15th row and 4th column (I need to see the R code!)
Filter the full pirates data so that it just includes pirates with more than 3 parrots and save to a new variable (see the tutorial..).
- What is the average number of tattoos of pirates with more than 3 parrots
- How many 3+ parrot owning, male pirates also have more than 3 tattoos.
Remove the 17th row and overwrite
Remove the row containing the tallest pirate (let’s say the data was entered incorrectly)
Challenge 3: Public safety spending
Suburban towns often spend a large fraction of their municipal budgets on public safety services (police, fire, and ambulance). A taxpayers’ group felt that tiny towns were likely to spend large amounts per person because they have such small financial bases. The group obtained data on the per-capita (per-person) spending on public safety for 29 suburban towns in a metropolitan area, as well as the population of each town in units of 1000 people. If you used 10000 thats fine
They sent you the data in the file expenditure.xslx, which you can get from Canvas.
- Download this from canvas and put it into your lab 4 folder. If you are on the cloud, just download it for now (see step 2)
BEFORE you read a file into R, it is good to look at column names. It’s very frustrating in R when column names have spaces, special characters or anything else that is difficult to type. It makes it especially hard to refer to a column/variable by name, e.g. table$columnname. You can change this in R using the names() command. But much easier is to fix the issue BEFORE reading it into R. So:
Open
expenditure.xlsxin Excel and take a look! Rename the column titles so that no column names contains spaces/special characters & check you are happy with the data. Save and close. If you are on the cloud, upload to your Lab 4 project.Use TUTORIAL 10: Reading in data to read it into R.
Use inline code to write a sentence in your report telling me the number of towns in the sample and the average population of the sampled towns. (See Lab 3 / Tutorial 4.8, Inline code). Summarize what the aim of the study is (see above), the unit of analysis, the response and predictor variables and what the taxpayer’s group expects the results to be.
If the taxpayer’s group is correct, write (in a full sentence) whether you think the slope of Simple Linear regression model between your response and predictor should be negative or positive?
Make a professional looking scatter-plot of your response and predictor (good enough to give to the taxpayers group). Describe it fully using this to help (KHAN SCATTER DESCRIPTIONS:)
Use Tutorial 9 to fit a regression model to the data and save it as a variable called
model1. Examine the coefficients and the summary of the model fit using OLSRR (in the tutorial).In the text of your report, write formally write the model equation either using the equation knowledge from labs 2/3 or equatiomatic to extract the equation for the model as described in Tutorial 9.
Explain the slope and intercept within the context of the data. Explain if the slope in the output confirms the opinion of the community group?
Add the line of best fit to a new version of the scatter-plot. Explain why this initial regression might be misleading.
Use Tutorial 11 to remove the outlier. Repeat the linear regression and scatter-plot with the new data and save it as a variable called
model2. Explain how this has changed your assessment of the relationship between the variables.Normally, to calculate the correlation coefficient between two variables, we use the
cor()command or we could look at the output fromols_regress(). Let’s imagine that these have mysteriously broken. From only the information provided in the commandsummary(model2), explain how you can quickly calculate the correlation coefficient and state what it is.Look at the ANOVA table (middle part of
ols_regress(model2)oranova(model2)). Using the information provided there, calculate the R2 value.Test if the slope is significantly different to 1 (Monday-28 lecture). Show all your workings and professionally format any equations. Note, I mean is it different to 1! For half marks, you can test if it is different to zero.
Challenge 4: Mystery data
Download the mystery dataset from canvas into your lab 4 folder.
Read it into R using TUTORIAL 10: Reading in data and calculate the correlation coefficient.
Explain why this correlation coefficient is vastly inappropriate!
There is no show me something new this lab.
Submitting your Lab
Remember to save your work throughout and to spell check your writing (next to the save button).
Now, press the knit button for the final time.
If you have not made any mistakes in the code then R should create a html file in your lab 4 folder which includes your answers. If you look at your lab 4 folder, you should see this there - complete with a very recent time-stamp.
In that folder, double click on the html file. This will open it in your browser. CHECK THAT THIS IS WHAT YOU WANT TO SUBMIT.
If you are on R studio cloud, see Tutorial 1 for how to download your files
Now go to Canvas and submit BOTH your html and your .Rmd file in Lab 4.
Grading Rubric/checklist
See the table below for what this means - 100% is hard to get!
HTML FILE SUBMISSION - 10 marks
RMD CODE SUBMISSION - 10 marks
WRITING/CODE STYLE - 10 MARKS
Your code and document is neat and easy to read. LOOK AT YOUR HTML FILE IN YOUR WEB-BROWSER BEFORE YOU SUBMIT. There is also a spell check next to the save button. You have used headings and subheadings to make the report easier to follow.
You have written your answers below the relevant code chunk in full sentences in a way that is easy to find and grade. It is clear what your answers are referring to. You have used units throughout and fully explained your workings IN YOUR OWN WORDS (we put these through ‘Turn It In’.
LEAF ANALYSIS: 15 MARKS
You have successfully attempted/completed the 6 steps. 2 marks lost for each error.
FILTERING DATA: 15 MARKS
You have successfully attempted/completed the 5 steps. 2 marks lost for each error.
PUBLIC SAFETY Q1-Q7: 15 MARKS
You have successfully attempted/completed the 7 steps. 2 marks lost for each error.
PUBLIC SAFETY Q8-Q13: 15 MARKS
You have successfully attempted/completed the 6 steps. 2 marks lost for each error.
MYSTERY DATA: 10 MARKS
6/10 for reading into R and calculating the correlation coefficient. Final 4 for explaining why its wrong/inappropriate.
[100 marks total]
Overall, here is what your lab should correspond to:
| Grade | % Mark | Rubric |
|---|---|---|
| A* | 98-100 | Exceptional. Not only was it near perfect, but the graders learned something. THIS IS HARD TO GET. |
| NA | 96+ | You went above and beyond |
| A | 94+: | Everything asked for with high quality. Class example |
| A- | 90+ | The odd minor mistake, All code done but not written up in full sentences etc. A little less care |
| B+ | 87+ | More minor mistakes. Things like missing units, getting the odd question wrong, no workings shown |
| B | 84+ | Solid work but the odd larger mistake or missing answer. Completely misinterpreted something, that type of thing |
| B- | 80+ | Starting to miss entire/questions sections, or multiple larger mistakes. Still a solid attempt. |
| C+ | 77+ | You made a good effort and did some things well, but there were a lot of problems. (e.g. you wrote up the text well, but messed up the code) |
| C | 70+ | It’s clear you tried and learned something. Just attending labs will get you this much as we can help you get to this stage |
| D | 60+ | You attempt the lab and submit something. Not clear you put in much effort or you had real issues |
| F | 0+ | Didn’t submit, or incredibly limited attempt. |